The file system provides data organization, structural sharing among applications, and persistence across reboots. Disk hardware presents storage as a numbered sequence of 512-byte sectors, while xv6’s file system works in fixed-size blocks built on top of those sectors. Xv6 caches disk blocks in memory as struct buf objects, whose contents may temporarily differ from disk while a read is in progress or after software modifies a block before writing it back.
Xv6 divides the disk into a fixed layout:
- Block 0 is the unused boot sector.
- Block 1 is the superblock.
- The following blocks hold the log, inode blocks, bitmap blocks, and data blocks.
The superblock and initial file-system image are created by mkfs before xv6 boots.
The file system itself is constructed as a seven-layer hierarchy, where each level abstracts the layer below it and eventually exposes a uniform resource interface to user processes.
 Layers of the xv6 file system.
Layers of the xv6 file system.
Data resides on a block device structured into distinct regions:
- Block 0: Boot sector (unused by the file system)
- Block 1: Superblock containing filesystem metadata (total blocks, data blocks, inode count, log size)
- Log blocks: Designated area for transaction records
- Inode blocks: Packed arrays of file metadata structures
- Bitmap blocks: Bit array tracking free/allocated status of data blocks
- Data blocks: File contents and directory entries
Filesystem image layout:

As xv6 boots, the build creates the filesystem image.
- User programs are compiled first, such as
_init,_sh, and other commands mkfsruns on the host machine, not inside xv6mkfscreatesfs.img, the virtual disk image passed to QEMUfs.imgcontains the xv6 filesystem layout- Compiled user programs are packed into
fs.img /initexists insidefs.imgbefore the kernel ever boots- QEMU starts xv6 with both the kernel image and
fs.img
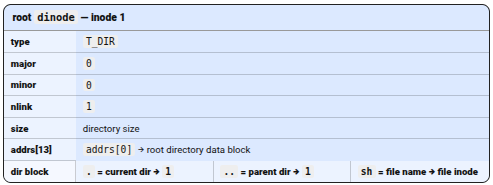
Root directory inode and its directory block:
Example user program inode:

Later, the virtio driver reads fs.img, and the first process execs /init.
The following diagram shows filesystem layers and how they interconnect:
--- config: layout: dagre --- flowchart TB classDef file fill:#FFFFFF,stroke:#111,stroke-width:3px,color:#111 classDef source fill:#E9F1FF,stroke:#111,stroke-width:2px,color:#111 classDef iface fill:#EDE7D4,stroke:#111,stroke-width:2px,color:#111 classDef backend fill:#F8F8F8,stroke:#111,stroke-width:2px,color:#111 subgraph MF["inode-table"] direction TB LOCK_FUNCS["inode locking<br/><br/>ilock<br/>iunlock"]:::iface ICACHE_FUNCS["inode cache<br/><br/>iinit<br/>iget<br/>idup<br/>iput<br/>iunlockput<br/>ireclaim"]:::iface end subgraph M["in-memory inode state"] direction LR ICACHE["itable<br/><br/>in-use cached inodes"]:::source INODE["struct inode<br/><br/>dev<br/>inum<br/>ref<br/>lock<br/>valid<br/>type<br/>major / minor<br/>nlink<br/>size<br/>addrs[]"]:::file SB_MEM["struct superblock sb<br/><br/>cached disk-layout metadata"]:::source end subgraph BF["files / directories / names interface"] direction TB PATH_FUNCS["Names layer<br/><br/>skipelem<br/>namex<br/>namei<br/>nameiparent"]:::iface DIR_FUNCS["Directories layer<br/><br/>namecmp<br/>dirlookup<br/>dirlink"]:::iface DATA_FUNCS["Files layer: content interface<br/><br/>bmap<br/>readi<br/>writei"]:::iface META_FUNCS["Files layer: inode<br/><br/>ialloc<br/>iupdate<br/>itrunc<br/>stati"]:::iface end subgraph LF["log transaction interface"] direction TB LOG_FUNCS["transaction boundary<br/><br/>initlog<br/>begin_op<br/>end_op"]:::iface LOG_WRITE_FUNCS["physical redo-log<br/><br/>log_write<br/>commit<br/>write_log<br/>write_head<br/>install_trans<br/>recover_from_log<br/>read_head"]:::iface end subgraph LM["in-memory log state"] direction LR LOG_STATE["struct log<br/><br/>lock<br/>start<br/>outstanding<br/>committing<br/>dev<br/>lh"]:::source LOG_HDR_MEM["logheader in memory<br/><br/>n<br/>block[]"]:::source end subgraph DF["raw block + superblock"] direction TB SUPER_FUNCS["superblock loading<br/><br/>readsb<br/>fsinit"]:::iface BLOCK_FUNCS["raw block allocator<br/><br/>balloc<br/>bzero<br/>bfree"]:::iface end subgraph BCI["buffer cache interface"] direction TB BC_FUNCS["buffer cache API<br/><br/>binit<br/>bread<br/>bwrite<br/>brelse<br/>bpin<br/>bunpin"]:::iface end subgraph BCS["buffer cache state"] direction LR BCACHE["bcache LRU list<br/><br/>cached disk blocks in memory"]:::source BUF["struct buf<br/><br/>valid<br/>disk<br/>dev<br/>blockno<br/>refcnt<br/>lock<br/>prev / next<br/>data[BSIZE]"]:::source end subgraph D["on-disk file-system source + device"] direction LR SUPER_DISK["super block<br/><br/>disk layout metadata"]:::source LOG_DISK["log blocks<br/><br/>header + logged block copies"]:::source DINODE["inode blocks<br/><br/>array of struct dinode"]:::source BITMAP["free bitmap blocks<br/><br/>block allocation bits"]:::source DATA_BLOCKS["data blocks<br/><br/>file bytes<br/>directory dirents<br/>indirect blocks"]:::source DISK_DEVICE["virtio block device"]:::backend end MF -->|keeps references in| M BF -->|uses locked inodes from| M BF -->|wraps modifying calls in| LF BF -->|gets disk blocks via| BC_FUNCS DF -->|logs bitmap/superblock writes through| LF DF -->|gets raw disk blocks via| BC_FUNCS LF -->|tracks active transaction in| LM LF -->|write_log writes home blocks to log<br>install_trans copies committed blocks back home| BC_FUNCS BC_FUNCS -->|returns locked buffers from| BCACHE BCACHE -->|linked list of| BUF BUF -->|transferred by virtio_disk_rw<br>reads from and writes to| DISK_DEVICE ICACHE -->|holds| INODE LOG_STATE -->|contains| LOG_HDR_MEM
Buffer Cache
The buffer cache synchronizes access to disk blocks and caches popular blocks in memory. xv6 keeps at most one cached buffer per disk block, so reads see recent writes and buffer locks can safely act as per-block locks.
- A doubly-linked LRU list of fixed buffer slots tracks recently used blocks
- A spinlock protects cache-wide metadata
- Each buffer has its own sleep-lock protecting its block contents so code can sleep during disk I/O
The buffer cache stores cached copies of disk blocks in memory. It holds 30 buffers total.
bcache is the global buffer-cache state.
| Field | Meaning |
|---|---|
lock | Protects cache-wide metadata. |
buf[NBUF] | Fixed array of 30 buffer objects. |
head | Dummy list node for the LRU list. |
head.next | Points toward the most recently used buffer. |
head.prev | Points toward the least recently used buffer. |
Each struct buf represents one cached disk block.
| Field | Meaning |
|---|---|
valid | Says whether data contains real disk contents. |
disk | Set while the virtio disk driver owns the buffer during I/O. |
dev | Disk device number. |
blockno | Block number on that device. |
lock | Sleeplock for this buffer’s contents. |
refcnt | Number of active users of this buffer. |
prev, next | Links for the LRU list. |
data[BSIZE] | Cached disk block contents. |
When a block is requested,
- cache first searches for an existing matching buffer.
- if none exists, it recycles the least recently used unused buffer,
- rewrites its metadata,
- clears the valid flag, and
- marks it referenced. A nonzero reference count prevents recycling. If every buffer is busy, xv6 panics rather than sleeping for one.
Logging
Many file-system operations update several disk blocks. A crash after only some writes can leave the disk inconsistent. Xv6 avoids this by logging all writes for an operation before installing them in their real disk locations.
The log lives at a fixed location recorded in the superblock.
- A header block records the home sector number for each logged block
- A count of
0means no committed transaction is present - A nonzero count means the log contains a complete committed transaction
The logging protocol wraps each file-system operation:
- An operation waits if a commit is running or if there is not enough reserved log space
- Modified buffers are recorded in the in-memory log and pinned in the cache; repeated writes to the same block collapse into one log slot
- When all operations complete, a commit begins
Commit has one critical point: writing the log header with a nonzero count. Before that point, recovery ignores the log and the operation disappears. After that point, recovery replays the logged writes and the operation appears completely.
- Modified buffers are copied from the cache to the on-disk log region
- The nonzero header is written to commit the transaction
- Logged blocks are copied to their home locations
- The header count is cleared to zero, erasing the transaction
Recovery runs during boot before user processes start. If the header count is nonzero, it installs the transaction and clears the log. This makes each committed transaction atomic with respect to crashes.
Xv6 can group writes of multiple complete system calls into one transaction, but commits only when no file-system calls are active. The fixed log size limits how many distinct blocks a transaction can contain, so large writes are split into smaller transactions.
Inode Layer
An inode identifies a file, directory, or device independently of its name. The term refers both to the on-disk struct dinode and to the in-memory struct inode.
- On-disk inodes are packed into the inode-block region and addressed by inode number
typedistinguishes files, directories, devices, and free inodes (zero type)nlinkcounts directory entries pointing at the inodesizerecords file length in bytesaddrsrecords the direct and indirect data block numbers
The inode table holds only inodes that kernel code currently references, such as open files and current working directories. It mainly synchronizes active inodes; caching is secondary because the buffer cache already keeps hot inode blocks in memory.
Xv6 separates inode references from inode locking:
- A lock ensures each active inode appears in memory at most once and protects reference counts
- A reference returns a non-exclusive pointer and increments the count; the pointer remains valid until released
- A sleep-lock acquires the inode and loads the on-disk copy if needed
- The sleep-lock is released to make it available for other threads
- Modified metadata is written back to disk
- The last reference, when no links remain, truncates the file, marks it free, and writes to disk
This split lets many code paths hold stable inode pointers while only one thread at a time edits metadata. It also avoids deadlocks during operations that need more than one inode.
The last inode reference drop may write to disk, so even read-looking operations must run inside a log transaction if they might trigger this. Xv6 does not fully recover unlinked-but-still-open files after a crash, so such inodes can remain allocated on disk without any directory entry.
File contents are mapped through the inode’s address array:
- The first set of entries point directly to data blocks
- The final entry points to an indirect block containing more block numbers
- A zero block number means no block is allocated at that position
- A logical block to disk block mapping may allocate direct, indirect, or data blocks on demand
- A file free releases all direct blocks, all blocks named by the indirect block, and the indirect block itself
Higher-level inode I/O uses this mapping:
- A read checks bounds, maps each file block, and copies bytes from cached buffers to the destination
- A write maps or allocates blocks, copies bytes into cached buffers, and grows the file size when writing past the old end
- Device inodes bypass normal file data blocks and dispatch through the device table
- Metadata is copied into the user-visible stat structure
The raw block allocator uses the on-disk bitmap:
- A block allocation scans bitmap blocks for a free bit, marks it allocated, and returns the block
- A block deallocation clears the bitmap bit for a released block
- Bitmap changes rely on buffer cache locks and must occur inside an active log transaction
struct dinode is not a .bss object.
struct dinodeis only the on-disk inode layout- The type definition does not allocate global RAM by itself
- Disk inode bytes live inside
fs.img - When a disk inode block is read, those bytes sit inside
buf.data - Filesystem code can then treat part of
buf.dataas astruct dinode struct inodeis the cached in-memory working copy stored initable.inode[NINODE]
struct dinode is the on-disk inode format.
| Field | Meaning |
|---|---|
type | File type. A zero type means the disk inode is free. |
major, minor | Device numbers for device files. |
nlink | Number of directory links to this inode. |
size | File size in bytes. |
addrs[NDIRECT+1] | Direct block addresses plus one indirect block address. |
itable is the global inode-table state.
| Field | Meaning |
|---|---|
lock | Protects allocation and lookup of inode-table entries. |
inode[NINODE] | Fixed array of in-memory inode objects. |
Each struct inode is an in-memory copy of one on-disk inode.
| Field | Meaning |
|---|---|
dev | Device containing the inode. |
inum | Inode number on that device. |
ref | Number of active references to this in-memory inode. |
lock | Sleeplock for this inode’s contents. |
valid | Says whether inode contents have been loaded from disk. |
type | File type copied from disk. |
major, minor | Device numbers for device inodes. |
nlink | Number of directory links to this inode. |
size | File size in bytes. |
addrs[NDIRECT+1] | Direct and indirect data-block addresses. |
Directory Layer
Directories are files whose inode type marks them as directories. Their data is a sequence of fixed-size directory entry records.
- Each entry stores an inode number and a name
- Names are NUL-terminated and limited in length
- An inode number of zero marks a free slot
A directory lookup scans a locked directory for a matching name. If it finds one, it stores the entry’s byte offset and returns the target inode through a reference, but leaves that inode unlocked. This avoids deadlock: a lookup for the current directory would otherwise try to lock the same directory twice, and the parent directory can create more complex multi-directory locking cycles.
A directory link adds a new entry. It first rejects duplicate names, then searches for a free slot; if none exists, it appends at the end of the directory. The new entry is written with the provided name and inode number.
Directories provide single-level naming, but users interact with deep hierarchical paths that require iterative evaluation.
Pathname Layer
Pathname lookup resolves multi-component paths by applying directory lookup to one component at a time.
- A full path lookup returns the inode named by the complete path
- A parent path lookup stops before the final component, returns the parent directory inode, and captures the final name
- Both use a shared traversal loop
The traversal first chooses the starting inode: absolute paths begin at the root, relative paths begin at the current working directory. It then loops over path components.
Each iteration follows the same pattern:
- Lock the current inode so its type and contents are available
- Verify the current inode is a directory
- Stop early for a parent lookup when the next component is the final one
- Use directory lookup to get an unlocked referenced inode for the next component
- Unlock and release the current inode before moving to the next inode
This design allows lookups in different directories to proceed concurrently and avoids deadlock. A directory lookup returns an inode reference, so the next inode cannot be deleted while the traversal drops the current directory lock. The traversal then locks only the next inode, which avoids relocking the same inode for the current directory and avoids multi-directory lock cycles involving parent directories.
Pathnames successfully identify specific files and directories, which are then abstracted alongside other I/O streams into file descriptors for user processes.
Real World
Real file systems solve the same problems as xv6, but with more scalable data structures, better failure handling, and richer resource abstractions.
Buffer caches still provide caching and synchronization, but modern systems use more efficient lookup and eviction structures than xv6’s simple LRU list. They are often integrated with the virtual memory system to support memory-mapped files.
Production logging systems allow more concurrency, avoid logging whole blocks for tiny changes, and batch disk writes more efficiently. Logging is not the only crash-recovery strategy: older systems used tools to scan and repair the whole file system after reboot, but log replay is usually faster and gives cleaner atomicity.
The inode and directory model has persisted into modern systems, but large directories use balanced trees instead of linear scans. Real systems handle disk failures gracefully instead of panicking, isolating damaged files, relying on redundancy, or reporting recoverable I/O errors.
Modern storage spans multiple disks and grows dynamically through RAID, volume managers, or integrated designs like ZFS. Xv6 assumes one fixed-size disk. Modern Unix-like systems expose many non-disk resources through file operations - named pipes, network sockets, network file systems, virtual file systems - dispatching through operation tables instead of hard-coded type branches.