A process is the fundamental unit of isolation, shielding an application’s memory, CPU state, and file descriptors from interference by other processes. A process bundles two foundational architectural illusions:
- Private Address Space: Simulates private physical memory using hardware page tables.
- RISC-V page tables translate virtual addresses utilized by instructions into physical addresses on the RAM chip.
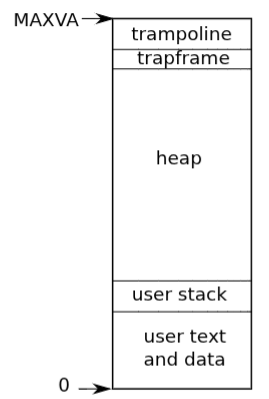
- The layout begins at virtual address zero with instructions, global variables, the stack, and the heap.
- The address space is bounded by hardware translation limits; xv6 uses 38 bits of addressable space, establishing a maximum virtual address of (
MAXVA). - The top pages of the address space are reserved for a trampoline page (managing user/kernel transitions) and a trapframe page (saving user state).
- Private CPU (Thread): Simulates dedicated processor execution.
- Each process contains a thread of execution that tracks local variables and return addresses on stacks.
- A process actively alternates between two stacks: a user stack for user-space computation, and a kernel stack used exclusively during system calls and interrupts.
- The kernel stack is protected from user-space access to ensure the kernel can execute safely even if the user stack is compromised.
- Kernel state for each process is centralized in a
procstructure, containing references to the process’s page table (p->pagetable), kernel stack (p->kstack), and run state (p->state). - During a system call, hardware elevates the privilege level, switches the program counter to the kernel entry point, executes on the kernel stack, and subsequently utilizes the
sretinstruction to lower privileges and resume the user thread.
Layout of a process’s virtual space:
Any operating system runs more processes than it has CPUs, so the CPUs must be time-shared among processes. The goal is to make this transparent: each process should have the illusion of its own virtual CPU. xv6 achieves this through multiplexing, switching each CPU between processes in two situations:
- When a process waits for I/O, a child to exit, or sleeps, xv6 switches to another process voluntarily.
- When a process computes for too long without sleeping, xv6 uses periodic hardware timer interrupts to force a switch.
This creates the same kind of illusion that virtual memory creates for physical memory: each process believes it has exclusive access to a resource it actually shares.
The Process State
The struct proc holds all kernel state for one process.
| Field | Meaning |
|---|---|
lock | Protects this process slot. |
state | Current process state: UNUSED, USED, SLEEPING, RUNNABLE, RUNNING, or ZOMBIE. |
chan | Sleep channel if the process is sleeping. |
killed | Set when the process has been marked for termination. |
xstate | Exit status reported to the parent. |
pid | Process ID. |
parent | Parent process pointer. |
kstack | Virtual address of this process’s kernel stack. |
sz | Size of the process’s user memory in bytes. |
pagetable | User page table for this process. |
trapframe | Saved user register state for trap entry and return. |
context | Saved kernel context used by swtch. |
ofile[NOFILE] | Open file table for this process. |
cwd | Current working directory inode. |
name[16] | Process name for debugging. |
CPU State
On a uniprocessor, one global pointer to the current process would be enough. On a multi-core machine, each core may run a different process, so xv6 needs per-CPU state. struct cpu is xv6’s per-hart bookkeeping object: it records the process currently running on this CPU, the saved scheduler context used when switching back from a process, and the interrupt state needed for nested critical sections.
mycpu finds the current CPU’s struct cpu by reading the tp register. tp holds the hardware thread ID (hartid), which xv6 uses as an index into the cpus[].
Keeping tp correct across all transitions requires care:
mstartsetstpearly in the boot sequence while still in machine mode.usertrapretsavestpinto the trampoline page before returning to user space, since user code could modify it.uservecrestores the savedtpwhen entering the kernel from user space.
The result of mycpu is fragile. A timer interrupt could move the current thread to another CPU, making the returned pointer stale. Callers must disable interrupts before calling mycpu and keep them disabled until they finish using the result.
myproc returns the struct proc running on the current CPU. It disables interrupts, calls mycpu, reads c->proc, and then re-enables interrupts. Unlike the struct cpu pointer from mycpu, the returned struct proc pointer remains valid after interrupts are re-enabled, since the process object itself does not change when the process moves between CPUs.
| Field | Meaning |
|---|---|
proc | Process currently running on this CPU, or 0 if none. |
context | Saved scheduler context used when switching back from a process. |
noff | Nesting depth of push_off interrupt-disable sections. |
intena | Whether interrupts were enabled before the first push_off. |
Locks
The p->lock is the central process lock in xv6. It protects fields that other processes and scheduler threads can observe or modify:
p->state: current lifecycle state.p->chan: sleep channel.p->killed: pending termination flag.p->xstate: exit status reported to the parent.p->pid: process identifier.
More importantly, p->lock protects the invariants that make process creation, scheduling, sleeping, waking, killing, and exit safe across multiple CPUs.
Core responsibilities:
- ensures only one CPU runs a
RUNNABLEprocess and keeps state/context transitions safe acrossswtch. - protects
proc[]allocation, creation, destruction, and slot reuse. - prevents
waitfrom collecting aZOMBIEchild before the child has yielded for the last time. - works with the condition lock so
wakeupcannot miss a process entering sleep. - keeps the victim stable while
killwritesp->killed, and updatesp->state. p->parentis the exception, protected by the globalwait_lockinstead ofp->lock.
Characteristics of wait_lock:
- protects
p->parentwhile parents write it and other processes search for child processes. - acts as the condition lock for
wait. - works with
p->lockto hide a child until it is safelyZOMBIE. - must be global because a process cannot safely identify its parent before holding the lock.
- serializes parent-child exit races and ensures
initis woken when it inherits orphaned children.
Process Initialization
A process initialization has two layers:
- the kernel prepares the global process table so every slot is known, locked, and marked
UNUSED userinitclaims one slot for the first process and marks itRUNNABLE;- the process does not become
/inituntil the scheduler runs it and entersforkret.
This first process does not contain user code yet.
- The scheduler will later choose this
RUNNABLEprocess - The first context switch enters
forkret forkretruns in kernel mode on this process’s kernel stack- The first
forkretcall runsfsinit(ROOTDEV)because filesystem initialization may sleep - After the filesystem is ready,
forkretcallskexec("/init", ...) kexecloads/initfrom the filesystem into the process’s user address space- The trampoline return path then enters user mode
The delayed /init load comes from forkret:
- the first process reaches
forkretthrough the savedcontext.raset byallocproc - then the first
forkretcall runsfsinit(ROOTDEV)and - calls
kexec("/init", argv). - it builds a new user page table, loads the ELF image
- commits
p->pagetable,p->sz,trapframe->epc, andtrapframe->sp - then returns through the normal user-return path.
First process setup path:
| Step | Caller | Function | State | What happens next |
|---|---|---|---|---|
| 1 | userinit | Calls allocproc | UNUSED -> USED | A first process slot is prepared and returned locked. |
| 2 | userinit | p->cwd = / | Still USED | The kernel records this process as the special init process. |
| 3 | userinit | p->state | USED -> RUNNABLE | The scheduler can choose it. |
| 4 | userinit | release | Still RUNNABLE | Other CPUs and the scheduler can safely inspect the slot. |
A child creation uses the same allocated-process skeleton as the first process.
kforkcallsallocproc,- copies the parent’s user address space and trapframe,
- edits the child’s saved return value so
fork()returns0in the child, - duplicates open-file references
- and
cwd, - records
parentunderwait_lock, - and only then marks the child
RUNNABLE.
| Step | Caller | Function | State | What happens next |
|---|---|---|---|---|
| 1 | fork syscall | Calls allocproc | UNUSED -> USED | A child process slot is claimed and returned locked. |
| 4 | kfork | uvmcopy | Still USED | Parent user memory is copied into the child. |
| 5 | kfork | Copies parent trapframe | Still USED | Child starts with the same saved user registers. |
| 6 | kfork | np->tf->a0 = 0 | Still USED | fork() will return 0 in the child. |
| 7 | kfork | Duplicates open files | Still USED | Child shares references to the parent’s open files. |
| 8 | kfork | Duplicates cwd | Still USED | Child starts in the same current directory. |
| 9 | kfork | Copies process name | Still USED | Child gets the parent’s debug name. |
| 10 | kfork | release | Still USED | Child resource setup is complete. |
| 11 | kfork | np->parent = p | Still USED | Parent-child relationship is recorded under wait_lock. |
| 12 | kfork | acquire | Still USED | The child slot is locked again before state change. |
| 13 | kfork | np->state | USED -> RUNNABLE | The scheduler can choose the child. |
| 14 | kfork | release | Still RUNNABLE | Other CPUs and the scheduler can inspect the child. |
The diagram ties together process-table initialization, first-process setup, child creation, and the later exec path that turns the first runnable slot into /init.
flowchart LR classDef process fill:#F3EFE2,stroke:#111,stroke-width:2px,color:#111 classDef file fill:#FFFFFF,stroke:#111,stroke-width:3px,color:#111 classDef source fill:#E9F1FF,stroke:#111,stroke-width:2px,color:#111 classDef iface fill:#EDE7D4,stroke:#111,stroke-width:2px,color:#111 classDef backend fill:#F8F8F8,stroke:#111,stroke-width:2px,color:#111 classDef state fill:#E8F7E8,stroke:#111,stroke-width:2px,color:#111 subgraph STATE["core process setup state"] direction TB PTABLE["proc[NPROC]<br/><br/>global process table<br/>one struct proc slot per possible process"]:::source INITPROC["initproc<br/><br/>global pointer to first user process<br/>later adopts orphaned children"]:::source PIDLOCK["pid_lock<br/><br/>serializes nextpid allocation"]:::source WAITLOCK["wait_lock<br/><br/>protects parent/child links<br/>and wait/exit ordering<br/>must be acquired before child p->lock"]:::source PROCSTRUCT["struct proc<br/><br/>lock, state, pid, parent<br/>kstack, sz, pagetable<br/>trapframe, context<br/>ofile[], cwd, name"]:::file TRAPFRAME["trapframe<br/><br/>saved user-mode register state<br/>epc = user PC<br/>sp = user stack pointer<br/>a0/a1 = return value / args<br/>kernel_* fields used on next trap"]:::file CONTEXT["context<br/><br/>saved kernel context for swtch<br/>ra, sp, s0-s11<br/>new procs start with ra = forkret"]:::file SETUPSTATES["states touched here<br/><br/>UNUSED: free proc slot<br/>USED: allocated but not runnable<br/>RUNNABLE: ready for scheduler"]:::state end PROCSETUP["procinit<br/><br/>initialize pid_lock and wait_lock<br/>initialize each p->lock<br/>set p->state = UNUSED<br/>set p->kstack = KSTACK(index)"]:::iface subgraph CREATE["user process creation path"] direction TB ALLOCPROC["allocproc<br/><br/>find an UNUSED proc slot<br/>return with p->lock held<br/>assign pid using allocpid<br/>set p->state = USED<br/>allocate trapframe page<br/>create empty user pagetable<br/>map TRAMPOLINE and TRAPFRAME<br/>set context.ra = forkret<br/>set context.sp = top of kernel stack<br/><br/>on setup failure:<br/>freeproc and return 0"]:::iface ALLOCPID["allocpid<br/><br/>lock pid_lock<br/>return current nextpid<br/>increment nextpid<br/>unlock pid_lock"]:::iface FREEPROC["freeproc<br/><br/>requires p->lock held<br/>free trapframe and user pagetable<br/>clear pid, parent, name, chan<br/>clear killed and xstate<br/>set state = UNUSED"]:::iface USERINIT["userinit<br/><br/>create first user process<br/>p = allocproc()<br/>initproc = p<br/>p->cwd = namei("/")<br/>p->state = RUNNABLE<br/>release p->lock<br/><br/>note: /init is installed later by forkret"]:::iface KFORK["kfork<br/><br/>create child process<br/>child = allocproc()<br/>copy parent user memory<br/>copy parent trapframe<br/>set child trapframe.a0 = 0<br/>duplicate open files and cwd<br/>copy process name<br/><br/>parent link:<br/>release child p->lock<br/>acquire wait_lock<br/>child->parent = current process<br/>release wait_lock<br/><br/>make child runnable:<br/>reacquire child p->lock<br/>set state = RUNNABLE<br/>release child p->lock<br/>return child pid<br/><br/>on failure:<br/>freeproc and return -1"]:::iface end subgraph EXECENTRY["exec and first user entry path"] direction TB KEXEC["kexec(path, argv)<br/><br/>replace current process image<br/>open executable<br/>read and validate ELF header<br/>create new user pagetable<br/>load ELF program segments<br/>allocate guard page + user stack<br/>copy argv strings onto stack<br/>record argv pointer in trapframe.a1<br/>update process name<br/><br/>commit only after setup succeeds:<br/>p->pagetable = new pagetable<br/>p->sz = new memory size<br/>trapframe.epc = ELF entry<br/>trapframe.sp = new user stack pointer<br/>free old user pagetable/image<br/><br/>same struct proc continues<br/>return argc on success, -1 on failure"]:::iface FORKRET["forkret<br/><br/>first kernel code run by a new process<br/>scheduler enters here via context.ra<br/>scheduler still holds p->lock<br/>forkret releases p->lock<br/><br/>first call only:<br/>fsinit(ROOTDEV)<br/>p->trapframe->a0 = kexec("/init", argv)<br/>panic if /init exec fails<br/><br/>then returns to user space"]:::iface USERRETURN["return to user path<br/><br/>prepare_return:<br/>set stvec to trampoline uservec<br/>fill trapframe kernel_satp/kernel_sp/kernel_trap/kernel_hartid<br/>set sstatus for user mode<br/>set sepc = trapframe.epc<br/><br/>trampoline userret:<br/>switch to user pagetable<br/>restore user registers<br/>execute sret"]:::iface USERMODE["user mode<br/><br/>CPU resumes at trapframe.epc<br/>with user stack trapframe.sp<br/>and restored user registers"]:::state end PTABLE -- "contains many" --> PROCSTRUCT PROCSTRUCT -- "has one" --> TRAPFRAME PROCSTRUCT -- "has one" --> CONTEXT PROCSTRUCT -- "state field uses" --> SETUPSTATES PIDLOCK -- "protects" --> ALLOCPID WAITLOCK -- "protects parent assignment inside" --> KFORK PROCSETUP -- "initializes" --> PIDLOCK PROCSETUP -- "initializes" --> WAITLOCK PROCSETUP -- "initializes every slot in" --> PTABLE PROCSETUP -- "sets initial state" --> SETUPSTATES USERINIT -- "calls" --> ALLOCPROC USERINIT -- "sets global pointer" --> INITPROC USERINIT -- "marks first process RUNNABLE" --> SETUPSTATES ALLOCPROC -- "searches UNUSED slot in" --> PTABLE ALLOCPROC -- "gets pid from" --> ALLOCPID ALLOCPROC -- "allocates and attaches" --> TRAPFRAME ALLOCPROC -- "creates pagetable inside" --> PROCSTRUCT ALLOCPROC -- "initializes saved kernel context" --> CONTEXT ALLOCPROC -- "on setup failure calls" --> FREEPROC ALLOCPROC -- "context.ra points to" --> FORKRET KFORK -- "starts by allocating child" --> ALLOCPROC KFORK -- "copies address space and sz into child" --> PROCSTRUCT KFORK -- "copies and edits child trapframe" --> TRAPFRAME KFORK -- "sets child state RUNNABLE" --> SETUPSTATES KFORK -- "on allocation or uvmcopy failure" --> FREEPROC KEXEC -- "updates memory fields in" --> PROCSTRUCT KEXEC -- "sets epc, sp, a1 in" --> TRAPFRAME KEXEC -- "normal sys_exec returns through" --> USERRETURN FORKRET -- "first call only initializes fs and execs /init" --> KEXEC FORKRET -- "normal path after releasing p->lock" --> USERRETURN USERRETURN -- "enters" --> USERMODE
Lifecycle
A running process does not keep the CPU forever. It may
- voluntarily yield (for example, while waiting on a pipe that has no data),
- or the kernel may preempt it through a timer interrupt so other processes get a turn
xv6 uses
sleepandwakeup, sometimes called sequence coordination or conditional synchronization, to handle these transitions cleanly.
Sleep
sleep(chan, lk) puts the calling process to sleep on an arbitrary channel while holding the condition lock lk.
sleepacquiresp->lockwhile still holdinglk, then releaseslk- any concurrent
wakeupblocks onp->lockand cannot inspect the process until it is safelySLEEPING - once
p->lockis held alone,sleeprecordsp->chan, setsp->statetoSLEEPING, and - calls
schedto yield the CPU - on wakeup,
sleepreacquireslkbefore returning - callers wrap
sleepin awhileloop that rechecks the condition after every wakeup (this also handles spurious wakeups from unrelated channels)
Exit
A process that calls exit cannot vanish immediately as it’s parent must learn the exit status, and other processes may still hold references to it.
- The exiting process records its exit status,
- closes its resources,
- reparents its children to
initproc, - wakes its parent,
- sets
p->statetoZOMBIE, and - yields the CPU for the last time
- If the parent exits first,
reparentreassigns any orphans toinitproc, which perpetually callswait.
Wait
The parent calls wait to collect the child’s exit status and free the zombie slot.
waitacquireswait_lockas its condition lock,- then scans for children
- if it finds a
ZOMBIE, it copies the exit status, frees the child withfreeproc, - and returns its PID.
- if no child has exited, it sleeps on the parent itself and retries when woken.
- if no children exist, it returns
-1immediately.
Kill
kill does not destroy a process directly since the victim may be executing in a kernel critical section on another CPU.
- instead,
killsetsp->killedand, if the victim is sleeping, changes its state toRUNNABLE - may cause
sleepto return even though the condition has not been met, - the surrounding
whileloop rechecks and goes back to sleep if needed - when the victim next enters or exits the kernel,
usertrapchecksp->killedand callsexit
some sleep loops (e.g., inside a disk write sequence) do not check p->killed until the operation completes, so a killed process may linger; there is also a narrow race where kill sets p->killed just after the victim checks the flag but before it calls sleep, missing the kill until the next check
Wakeup
wakeup(chan) scans the process table and promotes every process sleeping on chan from SLEEPING to RUNNABLE, acquiring each p->lock in turn and upgrading matching sleepers.
- The lost wakeup problem: a process checks a condition, finds it false, and begins to sleep. Another thread makes the condition true and calls
wakeupbefore the first process finishes.wakeupfinds no sleeper and does nothing. - The solution:
sleepholds the condition lock until after it marks the processSLEEPING, so a concurrentwakeupeither sees the condition before the sleeper checks it or finds the process alreadySLEEPINGand cannot miss it
The diagram maps the lifecycle transitions among sleep, wakeup, kill, exit, wait, and their shared process-table state.
flowchart LR subgraph STATE["runtime process state"] direction LR PTABLE["proc[NPROC]<br><br>global process table<br>one struct proc slot per process<br><br>"] STATES["process states<br><br>RUNNABLE: can be scheduled<br>RUNNING: currently executing<br>SLEEPING: blocked on chan<br>ZOMBIE: exited, waiting for parent<br>UNUSED: free proc slot"] end subgraph BLOCKING["sleep / kill"] direction LR SLEEP["sleep(chan, lk)<br><br>acquire p->lock<br>release condition lock lk<br>set p->chan = chan<br>set p->state = SLEEPING<br>call sched()<br><br>after wakeup:<br>clear p->chan<br>release p->lock<br>reacquire lk"] KKILL["kkill(pid)<br><br>scan proc table for pid<br>set p->killed = 1<br>if victim is SLEEPING:<br>set p->state = RUNNABLE<br><br>does not destroy the process immediately"] end subgraph WAKEBLOCK["wakeup"] direction LR WAKEUP["wakeup(chan)<br><br>used here by:<br>kexit: wakeup(parent)<br>reparent: wakeup(initproc)<br><br>scan proc table<br>skip current process<br>for each process sleeping on chan:<br>acquire p->lock<br>set p->state = RUNNABLE<br>release p->lock"] end subgraph EXITWAIT["exit / wait / reparent / cleanup"] direction LR KEXIT["kexit(status)<br><br>current process exits<br>panic if initproc exits<br>close open files<br>release cwd<br>acquire wait_lock<br>reparent children<br>wakeup parent<br>acquire p->lock<br>set p->xstate = status<br>set p->state = ZOMBIE<br>release wait_lock<br>call sched()<br>never returns"] REPARENT["reparent(p)<br><br>called with wait_lock held<br>scan proc table<br>children of exiting process<br>are assigned to initproc<br>wakeup(initproc)"] KWAIT["kwait(addr)<br><br>parent waits for a child<br>acquire wait_lock<br>scan proc table for children<br><br>if child is ZOMBIE:<br>copy child xstate to user addr<br>free child with freeproc<br>return child pid<br><br>if no zombie child:<br>sleep(parent, &wait_lock)"] FREEPROC["freeproc(p)<br><br>requires p->lock held<br>free trapframe<br>free user pagetable<br>clear sz, pid, parent, name, chan<br>clear killed and xstate<br>set p->state = UNUSED"] end SLEEP -- sets chan and SLEEPING in --> PTABLE WAKEUP -- scans --> PTABLE WAKEUP -- matching sleepers become RUNNABLE --> STATES KKILL -- sets killed flag in --> PTABLE KKILL -- if SLEEPING, makes RUNNABLE --> STATES KEXIT -- uses --> REPARENT KEXIT -- wakeup(parent) --> WAKEUP REPARENT -- wakeup(initproc) --> WAKEUP KEXIT -- "sets state = ZOMBIE" --> STATES KWAIT -- scans children in --> PTABLE KWAIT -- if no zombie child, sleeps on parent --> SLEEP KWAIT -- frees zombie child through --> FREEPROC FREEPROC -- clears proc slot in --> PTABLE FREEPROC -- returns slot to UNUSED --> STATES PTABLE:::source STATES:::state SLEEP:::iface KKILL:::iface WAKEUP:::iface KEXIT:::iface REPARENT:::iface KWAIT:::iface FREEPROC:::iface classDef process fill:#F3EFE2,stroke:#111,stroke-width:2px,color:#111 classDef file fill:#FFFFFF,stroke:#111,stroke-width:3px,color:#111 classDef source fill:#E9F1FF,stroke:#111,stroke-width:2px,color:#111 classDef iface fill:#EDE7D4,stroke:#111,stroke-width:2px,color:#111 classDef backend fill:#F8F8F8,stroke:#111,stroke-width:2px,color:#111 classDef state fill:#E8F7E8,stroke:#111,stroke-width:2px,color:#111
Scheduler
At this point, process creation has only made a process eligible to run. The transition to actually executing is the scheduler’s job:
The scheduler runs as a special per-CPU thread, executing a loop that finds a runnable process, runs it until it yields, and repeats.
scheduler
- Runs forever on each CPU after boot setup.
- Updates
struct cpu: usesc->procandc->contextfor this CPU. - Clears
c->procwhen the CPU is not running a process. - Briefly enables then disables interrupts before scanning.
- This avoids deadlock when all processes sleep, while still avoiding a race with
wfi. - Scans
proc[]for aRUNNABLEprocess. - Locks each process slot before checking its state.
- Changes the chosen process to
RUNNING. - Stores the process in this CPU’s
c->proc. - Calls
swtch(&c->context, &p->context)to enter the process. swtchsaves the scheduler’s CPU context inc->context.- The process must change its own state before switching back.
- Clears
c->procafter the process returns to the scheduler. - Resumes scanning when the process yields, sleeps, or exits back to the scheduler.
- Runs
wfiif no process is runnable, so the CPU waits for an interrupt.
If no process is runnable, the CPU executes wfi and waits for an interrupt.
When a runnable process is found:
p->statechanges fromRUNNABLEtoRUNNINGc->procis set to that processswtch(&c->context, &p->context)saves the scheduler context and loads the process context- The process starts or resumes in kernel mode
- When the process later gives up the CPU, it switches back to
c->context c->procis cleared after control returns to the scheduler
swtch
A context switch from one user process to another involves four steps:
- A user/kernel transition on the old process.
- A context switch to the CPU’s scheduler thread.
- A context switch to the new process’s kernel thread.
- A trap return to user space.
Each CPU has its own dedicated scheduler thread with its own stack and saved registers. This is necessary because it is not safe for the scheduler to run on the old process’s kernel stack: another core might wake that process and run it, and two cores executing on the same stack would be a disaster.
At the hardware level, a context switch saves the current thread’s registers and restores a previously saved set. The stack pointer and return address are among the saved registers, so the CPU switches both stacks and the code it is executing. The swtch function performs this save and restore for kernel thread switches. It operates on struct context, which holds 32 callee-saved RISC-V registers. Caller-saved registers are handled by the C compiler, which saves them on the stack before calling swtch.
swtch
- Assembly context-switch.
- Saves current
ra,sp, and callee-saved registers into the old context. - Loads
ra,sp, and callee-saved registers from the new context. scheduleruses it to enter a process.scheduses it to return to the scheduler.
swtch only switches kernel contexts.
- It saves
ra,sp, and callee-saved registers into the oldstruct context - It loads
ra,sp, and callee-saved registers from the newstruct context - It does not switch user registers directly
- User registers are handled separately by the trapframe and trampoline path
Key properties of swtch:
- It takes two arguments, a pointer to the old context and a pointer to the new context. It saves current registers into the old, loads from the new, and returns.
- It saves the
raregister (the return address) rather than the program counter directly. - When it returns, it resumes at the instruction pointed to by the restored
ra, on the new thread’s stack.
The flowchart maps the scheduler loop, the interactions between scheduler elements and the process states they touch.
--- config: layout: dagre --- flowchart LR classDef actual fill:#EDE7D4,stroke:#111,stroke-width:2px,color:#111 classDef backend fill:#F8F8F8,stroke:#111,stroke-width:2px,color:#111 classDef concept fill:#F3E8FF,stroke:#111,stroke-width:2px,color:#111 classDef source fill:#E9F1FF,stroke:#111,stroke-width:2px,color:#111 classDef file fill:#FFFFFF,stroke:#111,stroke-width:3px,color:#111 classDef state fill:#E8F7E8,stroke:#111,stroke-width:2px,color:#111 subgraph STATE["scheduler state"] direction LR CTABLE["cpus[NCPU]<br/><br/>per-CPU scheduler state<br/>c->proc = current process<br/>c->context = scheduler context<br/>noff/intena = interrupt nesting state"]:::source PTABLE["proc[NPROC]<br/><br/>global process table<br/>scheduler scans this table"]:::source CONTEXT["context<br/><br/>saved kernel registers<br/>ra, sp, s0-s11<br/><br/>swtch exchanges scheduler context<br/>and process context"]:::file STATES["process states<br/><br/>RUNNABLE: can be chosen<br/>RUNNING: currently on CPU<br/>SLEEPING: blocked elsewhere<br/>ZOMBIE: exited elsewhere<br/>USED/UNUSED: not runnable"]:::state end subgraph PICK["scheduler loop"] direction LR SCHEDULER["scheduler()<br/><br/>per-CPU infinite loop<br/>enable interrupts<br/>scan proc table<br/>acquire p->lock<br/><br/>if p->state == RUNNABLE:<br/>set p->state = RUNNING<br/>set c->proc = p<br/>swtch into process<br/><br/>when process returns:<br/>clear c->proc<br/>release p->lock"]:::actual SWTCHIN["swtch(c-context, p-context)<br/><br/>low-level context switch<br/><br/>scheduler to process<br/>save scheduler context<br/>restore process context"]:::backend RUNNING["process running in kernel<br/><br/>conceptual state point<br/><br/>process context is active<br/>p->state is RUNNING<br/>c->proc points to p"]:::concept IDLE["idle path<br/><br/>conceptual scheduler case<br/><br/>no RUNNABLE process found<br/>scheduler executes wfi<br/>CPU waits until interrupt"]:::concept YIELD["yield()<br/><br/>timer-driven handoff<br/>acquire p->lock<br/>set p->state = RUNNABLE<br/>call sched()<br/>release p->lock"]:::actual LIFECYCLE["sleep / exit<br/><br/>conceptual entry from lifecycle paths<br/><br/>sleep sets state = SLEEPING<br/>exit sets state = ZOMBIE<br/>then both call sched()"]:::concept SCHEDFUNC["sched()<br/><br/>requires p->lock held<br/>requires state changed<br/>away from RUNNING<br/>requires interrupts disabled<br/><br/>switch back to scheduler"]:::actual SWTCHOUT["swtch(p-context, c-context)<br/><br/>low-level context switch<br/><br/>process to scheduler<br/>save process context<br/>restore scheduler context"]:::backend end subgraph FIRST["first-run path"] direction TB FORKRET["forkret<br/><br/>first kernel code run<br/>by a newly scheduled process<br/><br/>restored context.ra lands here<br/>forkret releases p->lock<br/>then returns toward user mode"]:::actual end SCHEDULER -. "uses CPU state" .-> CTABLE SCHEDULER -. "scans process table" .-> PTABLE PTABLE -. "state field uses" .-> STATES SWTCHIN -. "exchanges contexts" .-> CONTEXT SWTCHOUT -. "exchanges contexts" .-> CONTEXT SCHEDFUNC -. "uses CPU scheduler context" .-> CTABLE SCHEDULER -- "choose RUNNABLE process" --> SWTCHIN SCHEDULER -- "if none found" --> IDLE SWTCHIN -- "restores process context" --> RUNNING SWTCHIN -- "first scheduled run only" --> FORKRET RUNNING -- "timer interrupt" --> YIELD RUNNING -- "blocks or exits" --> LIFECYCLE YIELD -- "sets state = RUNNABLE" --> STATES YIELD -- "calls" --> SCHEDFUNC LIFECYCLE -- "calls" --> SCHEDFUNC SCHEDFUNC -- "calls" --> SWTCHOUT SWTCHOUT -- "returns inside scheduler()" --> SCHEDULER
Giving up the CPU
A process that wants to give up the CPU must follow a specific sequence before calling sched:
- Acquire its own process lock
p->lock. - Release any other locks it holds.
- Update its state in
p->state. - Call
sched.
The sched verifies these requirements, then calls swtch to save the current context and switch to the scheduler context. The scheduler then continues its loop:
- Finds the next runnable process.
- Sets
c->proc. - Marks it
RUNNING. - Calls
swtchto run it.
The typical flow during a timer-driven yield:
usertrapcallsyield.yieldcallssched.schedcallsswtch, saving the process’s context and switching to the per-CPU scheduler context.- When
swtchreturns, execution resumes insidescheduler, notsched, on the scheduler’s stack.
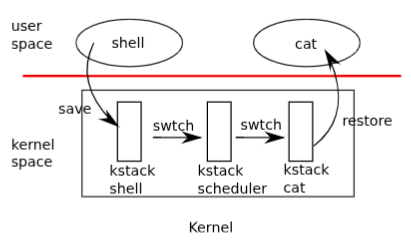
The sched and scheduler are co-routines: sched switches to scheduler, and scheduler almost always switches back to some thread that previously called sched. The one exception is a newly created process, whose context is set up by allocproc to jump to forkret on its first switch. forkret releases p->lock and returns to user space as if returning from fork.
The sequence diagram traces a full context switch from process A to process B through the timer interrupt or syscall paths.
sequenceDiagram autonumber participant A as Process A participant TR as trampoline.S participant UT as usertrap() participant YS as yield / sched participant SW as swtch.S participant SCH as scheduler() participant B as Process B alt Timer interrupt path Note over A: Mode = User<br/>Stack = A user stack A->>TR: timer interrupt Note over TR: Mode = Supervisor<br/>Stack = A user stack<br/>sp not switched yet TR->>TR: uservec TR->>TR: save registers to A trapframe TR->>TR: switch to kernel page table TR->>TR: load kernel_sp TR->>UT: jump to usertrap() Note over UT: Mode = Supervisor<br/>Stack = A kernel stack UT->>UT: save sepc to A trapframe.epc UT->>UT: handle timer interrupt UT->>YS: yield() else Voluntary yield syscall path Note over A: Mode = User<br/>Stack = A user stack A->>TR: ecall Note over TR: Mode = Supervisor<br/>Stack = A user stack<br/>sp not switched yet TR->>TR: uservec TR->>TR: save registers to A trapframe TR->>TR: switch to kernel page table TR->>TR: load kernel_sp TR->>UT: jump to usertrap() Note over UT: Mode = Supervisor<br/>Stack = A kernel stack UT->>UT: save sepc to A trapframe.epc UT->>UT: syscall() UT->>YS: yield syscall calls yield() end Note over YS: Mode = Supervisor<br/>Stack = A kernel stack YS->>YS: acquire A.lock YS->>YS: A.state = RUNNABLE YS->>YS: sched() YS->>SW: swtch(&A.context, &cpu.context) Note over SW: Mode = Supervisor<br/>Stack = A kernel stack SW->>SW: save ra, sp, s0-s11 to A.context SW->>SW: load ra, sp, s0-s11 from cpu.context SW-->>SCH: return Note over SCH: Mode = Supervisor<br/>Stack = CPU boot/scheduler stack SCH->>SCH: choose runnable B SCH->>SCH: B.state = RUNNING SCH->>SW: swtch(&cpu.context, &B.context) Note over SW: Mode = Supervisor<br/>Stack = CPU boot/scheduler stack SW->>SW: save ra, sp, s0-s11 to cpu.context SW->>SW: load ra, sp, s0-s11 from B.context SW-->>B: return Note over B: Mode = Supervisor<br/>Stack = B kernel stack B->>B: resume after previous swtch() B->>B: usertrapret() B->>B: set up return to user mode B->>TR: jump to userret Note over TR: Mode = Supervisor<br/>Stack = B kernel stack TR->>TR: switch to B user page table TR->>TR: restore registers from B trapframe TR->>TR: restore B user sp TR->>B: sret Note over B: Mode = User<br/>Stack = B user stack B->>B: resume user execution
Invariants
xv6 holds p->lock across calls to swtch, meaning the thread that acquires the lock is not the one that releases it. This breaks the usual locking convention but is necessary because p->lock protects invariants on the process’s state and context fields that do not hold during swtch itself. Without the lock, another CPU could see the process as RUNNABLE and start running it before swtch has finished, putting two CPUs on the same kernel stack.
The invariants p->lock enforces depend on the process state:
- RUNNABLE:
p->contextholds the saved registers, no CPU is executing on its kernel stack, and noc->procpoints to it. An idle scheduler must be able to pick it up safely. - RUNNING: the CPU registers hold the process’s values, and
c->procrefers to it. A timer interrupt must be able to yield safely at any point.
These invariants are the reason p->lock is often acquired in one thread and released in another. yield acquires it and scheduler releases it; scheduler acquires it and yield releases it. The lock must be held continuously across the transition to keep the invariants intact.
State Machine
The table lists every valid state transition and which code path drives it. The diagram below shows the same transitions as a graph.
State transition reference:
| Case | Caller / event | Main path | From | To |
|---|---|---|---|---|
| Give up CPU | Timer interrupt or process path | yield | RUNNING | RUNNABLE |
| Wait for event | Kernel code needing a condition | sleep | RUNNING | SLEEPING |
| Event happens | Producer or interrupt handler | wakeup | SLEEPING | RUNNABLE |
| Kill sleeping process | kill syscall path | kkill | SLEEPING | RUNNABLE |
| Exit current process | exit syscall path or fatal user condition | kexit | RUNNING | ZOMBIE |
| Reap child | Parent wait syscall path | kwait | ZOMBIE | UNUSED |
stateDiagram-v2 [*] --> UNUSED: init UNUSED --> USED: alloc USED --> UNUSED: alloc fails USED --> RUNNABLE: init / fork RUNNABLE --> RUNNING: schedule RUNNING --> RUNNABLE: yield RUNNING --> SLEEPING: sleep SLEEPING --> RUNNABLE: wakeup / kill RUNNING --> ZOMBIE: exit ZOMBIE --> UNUSED: wait / reap
Pipes
A pipe is a struct pipe with a lock, a circular buffer, and two counters (nread, nwrite). The counters distinguish full (nwrite == nread + PIPESIZE) from empty (nwrite == nread).
Simultaneous pipewrite and piperead on two CPUs show the sleep/wakeup pattern:
pipewritefills the buffer under the pipe lock. If full, it wakes readers on&pi->nreadand sleeps on&pi->nwrite.pipereadacquires lock, reads data, incrementsnread, and wakes writers on&pi->nwrite.
Separate channels for readers and writers avoid waking the wrong side, and both sides sleep in a while loop that rechecks the condition on wakeup.
Real World
xv6 uses round-robin scheduling, running each process in turn. Real operating systems implement priority-based policies that prefer high-priority runnable processes over low-priority ones. These policies grow complex quickly because competing goals such as fairness, throughput, and responsiveness must be balanced simultaneously. Complex policies can also produce unintended side effects:
- Priority inversion: a low-priority process holds a lock needed by a high-priority process, stalling it.
- Convoys: many high-priority processes queue behind a low-priority one that holds a shared lock; once formed, a convoy can persist for a long time.
The lost wakeup problem is a fundamental challenge for any sleep/wakeup mechanism. Different systems have tackled it differently:
- Early Unix simply disabled interrupts during sleep, which worked because Unix ran on a single CPU.
- xv6 and FreeBSD use an explicit lock passed into sleep.
- Plan 9’s sleep accepts a callback function that runs under the scheduling lock just before sleeping, as a last-minute condition check.
- Linux uses a wait queue with its own internal lock instead of a plain channel.
All of these share the same pattern: the sleep condition is protected by a lock that is dropped atomically as the process goes to sleep.
A related problem is the thundering herd: a single wakeup wakes all processes on a channel, and they all race to check the condition. Most condition variable implementations address this with two primitives:
signal: wakes one process.broadcast: wakes all.
Semaphores avoid this entirely by maintaining an explicit count of wakeups, which also eliminates lost wakeups and spurious wakeups.
xv6’s kill has known limitations:
- Some
sleeploops do not checkp->killed, so a killed process may not notice until its condition occurs. - A race exists:
killmay setp->killedjust after the victim checks the flag but before it callssleep, missing the kill entirely. - A real OS would maintain a free list for
procstructures; xv6 uses a linear scan for simplicity.
The process termination is complex. A process being killed may be deep inside the kernel with multiple stack frames that need cleanup. Some languages provide exception mechanisms for this; C does not. Unix uses signals: another process sends a signal to a sleeping process, causing it to return from the system call with -1 and EINTR, letting the application decide. xv6 does not support signals, so this complexity does not arise.