(datbase ko book ra distributed book ko mix xa yedi sense banena bhani dont mind)
A transaction defines a sequence of server operations that is guaranteed by the server to be atomic in the presence of multiple clients and server crashes.
The servers must guarantee that either the entire transaction is carried out and the results recorded in permanent storage or, in the case that one or more crashes, its effects are completely erased.
A transaction must be in one of the following states: 1. Active, the initial state; the transaction stays in this state while it is executing 2. Partially committed, after the final statement has been executed 3. Failed, after the discovery that normal execution can no longer proceed 4. Aborted, after the transaction has been rolled back and the database has been restored to its state prior to the start of the transaction 5. Committed, after successful completion
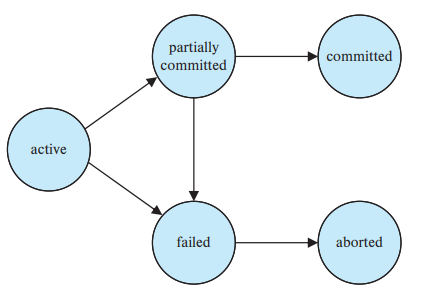
A transaction starts in the active state, when it finishes its final statement, it enters the partially committed state, at this point, the transaction has completed its execution, but it is still possible that it may have to be aborted, since the actual output may still be residing in main memory, and thus a hardware failure may preclude its successful completion.
The database system then writes out enough information to disk that, even in the event of a failure, the updates performed by the transaction can be re-created when the system restarts from the failure, when the last of the information is written out to a recovery file, the transaction enters the committed state.
A transaction enters the failed state after the system determines that the transaction can no longer proceed with its normal execution i.e. because of hardware or logical errors, such a transaction must be rolled back at this point, the system has two options:
- Can restart the transaction, but only if the transaction was aborted as a result of some hardware or software error that was not created through internal logic of the transaction, a restarted transaction is considered to be a new transaction
- Can kill the transaction, usually does so because of some internal logical error that can be corrected only by rewriting the application program, or because the input was bad, or because desired data were not found in the database.
Transaction processing systems usually allow multiple transactions to run concurrently. 1. Increase processor and disk utilization, leading to better transaction throughput: one transaction can be using the CPU while another is reading from or writing to the disk 2. Reduced average response time for transactions: short transactions need not wait behind long ones
A transaction in this context are subject to:
- Failure atomicity: A transaction either completes successfully, in which case the effects of all of its operations are recorded in the objects, or if it fails or is deliberately aborted has no effect at all.
- Durability: After a transaction has completed successfully, all its effects are saved in permanent storage. Data saved in a file will survive if the server process crashes.
- Isolation: Each transaction must be performed without interference from other transactions; in other words, the intermediate effects of a transaction must not be visible to other transactions.
To support the requirement for failure atomicity and durability, the objects must be recoverable; that is, when a server process crashes unexpectedly due to a hardware or a software error, the changes due to all the completed transactions must be available in permanent storage so that when the server is replaced by a new process, it can recover the objects to reflect the all-or-nothing effect.
One way of ensure isolation is to perform the transactions serially - one at a time, in some arbitrary order, unfortunately, aim for any server that supports transactions is to maximize concurrency. Therefore transactions are allowed to execute concurrently if this would have the same effect as a serial execution that is, if they are serially equivalent.
Serial equivalence
Database must control the interaction among the concurrent transaction actions to prevent them from destroying the consistency of the database: concurrency-control mechanisms. Schedules represent the chronological order in which instructions are executed in the system, consists of the all instructions of those transactions and they must preserve the order in which the instructions appear in each individual transaction
Can ensure consistency of the database under concurrent execution by making sure that any scheduler that is executed has the same effect as a schedule that could have occurred without any concurrent execution, that is the schedule should, in some sense be equivalent to a serial schedule, such schedules are called serializable schedules.
Conflict serializability:
In a schedule consisting of two consecutive instructions I and J, of transactions and respectively, if and refer to different data items, then can swap and without affecting the results of any instruction in the schedule, however conflict if they are operations by different transactions on the same data item, and at least one of these instructions is a write operation.
If a scheduler can be transformed into a schedule by a series of swaps of non conflicting instructions, we say that and are conflict equivalent.
Precedence graph to determine the conflict serializability of a schedule:
A directed graph where set of vertices consist of all the transactions participating in the schedule, set of edges consists of all edges for which either executes before executes or executes before executes or . Then,
-
If an edge exists in the precedence graph, then, in any serial schedule equivalent to , must appear before .
-
If the precedence graph for has a cycle, then schedule is not conflict serializable, if no cycles, then scheduler is conflict serializable.
-
Serializability order of the transactions can be obtained by finding a linear order consistent with the partial order of the precedence graph, called topological sorting. Thus need to construct the precendecne graph and to invoke a cycle detection algorithm.
View serializability:
Less stringent than conflict equivalence. Consider two schedules and , where the same set of transactions participates in both schedules, and are said to be view equivalent if three conditions are met:
- For each data item , if transaction reads the initial value of in schedule , then transaction must, in schedule , also read the initial value of .
- For each data item , if transaction executes in schedule , and if that value was produced by a operation executed by transaction , then the operation of must in schedule , also read the value of that was produced by same operation of transaction .
- For each data item , the transaction if any that performs the final in schedule must also perform the final in schedule .
Every conflict serializable schedule is also view serializable, but there are view serialiable schedules that are not conflict serializable.
Recoverability from aborts
Serially equivalent schedules only enforce isolation, right?
If a transaction has committed after it has seen the effects of another transaction that subsequently aborted, the situation is not recoverable. The strategy for recoverability is to delay commits until after the commitment of any other transaction whose uncommitted state has been observed.
Recoverable schedules: -What if a transaction fails? -A recoverable schedule is one where, for each pair of transactions and such that reads a data item previously written by , the commit operation of appears before the commit operation of .
The aborting of transaction may cause further transaction to be aborted. Such situations are called cascading aborts. To avoid cascading aborts, transactions are only allowed to read objects that were written by committed transactions.
Cascade-less schedules: Even if a schedule is recoverable, to recover correctly from the failure of transaction Ti, we may have to roll back several transactions.
Common Problems
Common problems in achieving serializability in concurrent systems in the context of banking example:
-
The lost update: euta le write garyo tesko mathi arko le gardiyo
-
Inconsistent retrievals: euta le write gardai xa tesko bich mai arko le read gardiyo
-
Dirty reads and premature writes: euta ko value read garisakya thiye tesle ta abort gariyo yar
Locks
Transactions must be schedules so that their effect on shared data is serially equivalent. A server can achieve serial equivalence of transactions by serializing access to the objects.
A simple example of a serializing mechanism is the use of exclusive locks. In this locking scheme, the server attempts to lock any object that is about to be used by any operation of a client’s transaction. If a client requests access to an object that is already locked due to another client’s transaction, the request is suspended and the client must wait until the object is unlocked.
Serial equivalence requires that all of a transaction’s accesses to a particular object be serialized with respect to accesses by other transactions. All pairs of conflicting operations of two transactions should be executed in the same order. To ensure this, a transaction is not allowed any new locks after it has released a lock.
The two phase locking can ensure that even when multiple transactions are executed concurrently, only acceptable schedules are generated, regardless of how the OS time-shares resources among the transaction.
Two-phase locking protocol is widely used concurrency control mechanism that ensures serializability. It is the extension of shared and exclusive locks mechanism which requires a transaction to have two phases:
- Growing phase: The first phase of each transaction is a growing phase during which it acquires locks but does not release any.
- Shrinking phase: The second is where the transaction releases locks but does not acquire any.
Initially, a transaction is in the growing phase, acquire locks as needed, once the transaction releases a lock, it enters the shrinking phase, and it can issue no more lock requests.
Serializability? 2PL ensures conflict serializability. The point in the schedule where the transaction has obtained its final lock (the end of its growing phase) is called the lock point of the transaction. Now transactions can be ordered according to their lock points - this ordering is, in fact, a serializability ordering for the transactions.
Recoverability and cascadelessness? Because transactions may abort, strict executions are needed to prevent dirty reads and premature writes. Under a strict execution regime, a transaction that needs to read or write an object must be delayed until other transactions that wrote the same object have committed or aborted. To enforce this, any locks applied during the progress of transaction are held until the transaction commits or aborts. When a transaction commits, to ensure recoverability, the locks must be held until all the objects it updated have been written to permanent storage. This is called strict two-phase locking.
- When an operation accesses an object within a transaction:
- If the object is not already locked, it is locked and the operation proceeds
- If the object has a conflicting lock set by another transaction, the transaction must wait until it is locked.
- If the object has a non-conflicting lock set by another transaction, the lock is shared and the operation proceeds.
- If the object has already been locked in the same transaction, the lock will be promoted if necessary and the operation proceeds.
- When a transaction is committed or aborted, the server unlocks all objects it locked for the transaction.
The granting of locks will be implemented by a separate object in the server that we call the lock manager.
Deadlocks and starvation
Use of locks can lead to deadlocks. A state in which each member of a group of transactions is waiting for some other member to release a lock. A wait-for-graph can be used to represent the waiting relationships between current transactions. In a wait-for-graph the nodes represent transaction and the edges represent wait-for relationships between transactions.
A system is in a deadlock state if there exists a set of transactions such that every transaction in the set is waiting for data item from another transaction in the same set. More precisely, there exists a set of waiting transactions set such that is waiting for a data item holds, and is waiting for a data holds and so on such that is waiting for a data item holds.
There are two principle methods for dealing with deadlock problem:
- Can use a deadlock prevention protocol to ensure that the system will never enter a deadlock state.
- Alternatively allow the system to enter a deadlock state, and then try to recover.
Prevention is commonly used if the probability that the system wwould enter a deadlock state is relatively high, otherwsie, detection and recovery are more efficeint.
Prevention: One approach ensures that no cyclic waits can occur by ordering the requests for locks, or requesting all locks to be acquired together. Another approach performs rollbacks instead of waiting for a lock whenever the wait could potentially result in a deadlock.
Detection and recovery: An algorithm that examines the state of the system is invoked periodically to determine whether a deadlock has occurred. When a deadlock is detected: some transaction will have to be rolled back (made a victim) to break deadlock, select that transaction as victim that will incur minimum cost. Starvation happens if same transaction is always chosen as victim
When a transaction is aborted (or rolled back), it will normally be restarted by the client program. But in schemes that rely on aborting and restarting transactions, there is no guarantee that a particular transaction will ever pass the checks, for it may come into conflict with other transactions for the use of objects each time it is restarted. The prevention of a transaction ever being able to commit is called starvation.
Timestamp ordering
The locking protocols determine the order between every pair of conflicting transactions at execution time by the first lock that both members of the pair request that involves incompatible modes. Another method for determining the serializability order is to select an ordering among transactions in advance.
With each transaction in the system, we associate a unique fixed timestamp denoted by . This timestamp is assigned by the database system before the transaction starts execution. If a transaction enters the system, then . Two simple methods for implementing this scheme:
- Use the value of the system clock as the timestamp; that is, a transaction’s timestamp is equal to the value of the clock when the transaction enters the system.
- Use a logical counter that is incremented after a new timestamp has been assigned; that is, a transaction’s timestamp is equal to the value of the counter when the transaction enters the system.
The timestamps of the transactions determine the serializability order. Thus, if , then the system must ensure that the produced schedule is equivalent to a serial schedule in which transaction appears before transaction .
To implement this scheme, we associate with each data item two timestamp values:
- W-timestamp(Q) denotes the largest timestamp of any transaction that executed write(Q) successfully.
- R-timestamp(Q) denotes the largest timestamp of any transaction that executed read(Q) successfully.
These timestamps are updated whenever a new read(Q) or write(Q) instruction is executed.
The timestamp-ordering protocol ensures that any conflicting read and write operations are executed in timestamp order. The protocol operates as follows:
- Suppose that transaction issues read(Q).
- If then, needs to read a value of that was already overwritten. Hence, the read operation is rejected and is rolled back.
- If then the read operation is executed, and is set to the maximum of and .
- Suppose that transaction issues write(Q).
- If , then the value of that is producing was needed previously, and the system assumed that value would never be produced. Hence, the system rejects the write operation and rolls back.
- If , then is attempting to write an obsolete value of . Hence, the system rejects this write operation and rolls back.
- Otherwise, the system executes the write operation and sets to .
Serializability? The timestamp-ordering protocol ensures conflict serializability. This is because conflicting operations are processed in timestamp order.
Recoverability and cascadelessness? The protocol can generate schedules that are not recoverable. However, it can be extended to make the schedules recoverable, in one of several ways. Recoverability and cascadelessness can be ensured by performing all writes together at the end of the transaction. The writes must be atomic in the following sense: While the writes are in progress, no transaction is permitted to access any of the data items that have been written.
Deadlock? The protocol ensures freedom from deadlock, since no transaction ever waits.
Starvation? However, there is a possibility of starvation of long transactions if a sequence of conflicting short transactions causes repeated restarting of the long transactions.
Optimistic Concurrency Control
In cases where a majority of transactions are read-only transactions, the rate of conflicts among transactions may be low. Thus, may of these transactions, if executed without the supervision of a concurrency control scheme, would nevertheless leave the system in a consistent state. A concurrent-control scheme imposes overhead of code execution and possible delay of transactions.
The optimistic control is based on the belief that conflicts between transactions are infrequent and most transactions can complete without the need for locking, which can lead to better overall system performance compared to other concurrency control like pessimistic locking.
It may be better to use an alternative scheme that imposes less overhead. A difficulty in reducing the overhead is that we do not know in advance which transactions will be involved in a conflict.
The validation protocol requires that each transaction executes in two or three different phases in its lifetime, depending on whether it is a read-only or an update transaction. The phases are, in order:
- Read-phase: During this phase, the system executes transaction . It reads the values of the various data items and stores them in variables local to . It performs all write operations on temporary local variables, without updates of the actual database. This is a copy of the most recently committed version of the object. The use of tentative versions allows the transaction to abort with no effect on the objects, either during the working phase or if it fails validation due to other conflicting transactions.
- Validation phase: The validation test is applied to transaction . This determines whether is allowed to proceed to the write phase without causing a violation of serializability. If a transaction fails the validation test, the system aborts the transaction.
- Write phase. If the validation test succeeds for transaction , the temporary local variables that hold the results of any write operations performed by are copied to the database. Read-only transactions omit this phase.
To perform the validation test, we need to know when the various phases of transactions took place. We shall, therefore associate following timestamps with each transaction :
- , the time when started its execution.
- , the time when finished its write phase.
- , the time when finished its read phase and started its validation phase.
We determine the serializability order by the timestamp-ordering technique, using the value of the timestamp . Thus, the value and, if , then any produced schedule must be equivalent to a serial schedule in which transaction appears before transaction .
The validation test for transaction requires that, for all transactions with , one of the following two conditions must hold:
- . Since completes its execution before started, the serializability is indeed maintained.
- The set of data items written by does not intersect with the set of data items read by , and completes its write phase before starts its validation phase i.e. This condition ensures that the writes of and do not overlap. Since the writes of do not affect the read of , and since cannot affect the read of , the serializability order is indeed maintained.
Recoverability and cascadelessness? The validation scheme automatically guards against cascading rollbacks, since the actual writes take place only after the transaction issuing the write has committed.
Deadlock and starvation? However, there is a possibility of starvation of long transactions, due to a sequence of conflicting short transactions that cause repeated restarts of the long transaction. To avoid starvation, conflicting transactions must be temporarily blocked to enable the long transaction to finish.
Comparison of methods for concurrency control
The timestamp ordering method is similar to two-phase locking in that both use pessimistic approaches in which conflicts between transactions are detected as each object is accessed. On the one hand, timestamp ordering decides the serialization order statically - when a transaction starts. On the other hand, two-phase locking decides the serialization order dynamically - according to the order in which objects are accessed. Timestamp ordering is better than strict two-phase locking for read-only transactions. Two-phase locking is better when the operations in transactions are predominantly updates.
When optimistic concurrency control is used, all transactions are allowed to proceed, but some are aborted when they attempt to commit, or in forward validation transactions are aborted earlier. This results in relatively efficient operation when there are few conflicts, but a substantial amount of work may have to be repeated when a transaction is aborted.
We saw how to make transactions recoverable, but how exactly to do recovery?
Recovery
A computer system, like any other device, is subject to failure from a variety of causes: disk crash, power outage, software error, a fire in the machine room, even sabotage, in any failure, information may be lost, therefore, the database system must take actions in advance to ensure that the atomicity and durability properties of transactions are preserved.
Durability requires that objects are saved in permanent storage and will be available indefinitely thereafter. Therefore an acknowledgement of client’s commit request implies that all the effects of the transaction have been recorded in permanent storage. Failure atomicity requires that effects of transactions are atomic even when the server crashes. Recovery is concerned with ensuring that a server’s objects are durable and that the service provides failure atomicity.
The requirements for durability and failure atomicity are not really independent of one another and can be dealt with mechanism of the recovery manager. The task of a recovery manager are:
- to save objects in permanent storage (in a recovery file) for committed transactions;
- to restore the server’s objects after a crash;
- to recognize the recovery file to improve the performance of recovery;
Corruption during a crash, random decay or a permanent failure can lead to failures of the recovery file, which can result in some of the data on the disk being lost. In such cases we need another copy of the recovery file.
Storage structure that information residing in stable storage is theoretically never lost which in practice is approximated by techniques that make data loss extremely unlikely. To implement stable storage, need to replicate the needed information in several non-volatile storage media (usually disk) with independent failure modes and update the information in a controlled manner to ensure that failure during data transfer does not damage the needed information. RAID systems guarantee that the failure of a single disk (even during data transfer) will not result in loss of data, simplest and the fastest form of RAID is the mirrored disk, which keeps two copies of each block on separate disks.
At each server, an intentions list is recorded for all of its currently active transactions – an intentions list of a particular transaction contains a list of the references and the values of all the objects that are altered by that transaction.
At the point when a participant says it is prepared to commit a transaction, its recovery manager must have saved both its intentions list for that transaction and the objects in that intentions list in its recovery file, so that it will be able to carry out the commitment later, even if it crashes in the interim.
Logging
In the logging technique, the recovery file represents a log containing the history of all the transactions performed by a server. The history consists of values of objects, transaction status entries and transaction intentions lists.
Several types of log records, an update log record describes a single database write with fields:
- Transaction identifier, which is the unique identifier of the transaction that performed the write operation.
- Data-item identifier, which is the unique identifier of the data item being written, typically it is located on disk of the data item, consisting of the block identifier of the block on which the data item resides and an offset within the block.
- Old value, which is the value of the data item prior to the write.
- New value, which is the value that the data item will have after the write.
We represent an update log record as indicating that transaction has performed a write on data item . had value before the write and has value after the write. Other special log records exist to record significant events during transaction processing, such as start of the transaction and the commit or abort of a transaction
. Transaction has started
Whenever a transaction performs a write, it is essential that the log record for that write be created and added to the log, before the database is modified. Once a log record exists, we can output the modification to the database if that is desirable.
(aba yesma immediate ra deferred modification ni hunxa)
When a system crash occurs, we must consult to the log to determine those transactions that need to be redone and those that need to be undone.
Major difficulties
- Search process is time-consuming.
- Most of the transactions that need to be redone have already written their updates into the database, although redoing them will cause no harm, it will nevertheless cause recovery to take longer.
A simple checkpoint scheme that
- does not permit any updates to be performed while the checkpoint is in progress and
- outputs all modified buffer blocks to disk when checkpoint is performed
- Output onto the stable storage all log records currently residing in memory.
- Output to the disk all modified buffer blocks. (proabably means to perform the logs before this checkpoint tara aru disk blocks lai ni flush gar bahenk huna sakxa)
- Output onto stable storage a log record of the form , where is a list of transactions active at the time of the checkpoint.
Transactions are not allowed to perform any update actions, such as writing to a buffer block or writing a log record, while a checkpoint is in progress
The purpose of making checkpoints is to reduce the number of transactions to be dealt with during recovery and to reclaim file space. Checkpointing can be done immediately after recovery but before any new transactions are started. However, recovery may not occur very often. Therefore, checkpointing may need to be done from time to time during the normal activity of a server.
There are two approaches to storing the data from the recovery file:
- In the first the recovery manager starts at the beginning and restores the values of all of the objects from the most recent checkpoint. It then reads the values of each of the objects and for committed transactions replaces the values of the objects. In this approach, the transactions are replayed in the order in which they were executed and there could be a large number of them.
- In the second approach, the recovery manager will restore a server’s objects by reading the recovery file backwards. The recovery file has been structured so that there is a backwards pointer from each transaction status entry to the next. The recovery manager uses transactions with committed status to restore those objects that have not yet been restored. It continues until it has restored all of the server’s objects. This has the advantage that each object is restored once only.
The presence of a record in the log allows the system to streamline its recovery process. After a system crash has occurred, the system examines the log to find the last record by searching the log backward, from the end of the log.
The redo or undo operations need to be applied only to transactions in and to all transactions that started execution after the record was written to the log.
REDO:
- The list of transactions to be rolled back, undo list is initially set to the list in the <\text{checkpoint } L>$ log record
- Whenever a normal log record of the form or a redo only log record of the form is encountered, the operation is redone, that is, the value is written to data item .
- Whenever a log record of the form is found is added to undo list.
- Whenever a log record of the form or is found, is removed from undo-list.
UNDO:
- Whenever it finds a log record belonging to a transaction in the undo-list, it performs undo actions just as if the log record had been found during the rollback of the failed instruction.
- When the system finds a log record for a transaction in undo list, it writes a log record and removes from undo list.
- The undo phase terminates once undo list becomes empty i.e. system has found log records for all transaction that were initially in undo list.