We require computers around the world to timestamp electronic commerce transactions consistently, each computer may have its own physical clock, but the clocks typically deviate, and we cannot synchronize them perfectly.
In order to know at what time of day a particular event occurred at a particular computer it is necessary to synchronize clock with an authoritative, external source of time, for example: an eCommerce transaction involves events at a merchant’s computer and at a bank’s computer, important for auditing process, that those events are timestamped accurately.
The absence of global physical time makes it difficult to know the order in which any pair of events occured, or whether they occured simultaneously.
We often need to know what state process A is in when process B is in a certain state, but we cannnot rely on physical clocks to know what is true at the same time, for ex, in object oriented systems, need to be able to establish whether references to a particular object can no longer exist - whether the object has become garbage in which case we can free its memory.
Establishing this requires observations of the states of processes to find out whether they contain references and of the communication channels between processes in case messages containing references are in transit.
(problem bhaneko chai, timestamping, which occured earlier, getting global state)
- Correct time stamping: Many distributed algorithms rely on the concept of time to make decisions or maintain consistency. For example, distributed databases use timestamps to determine the order of transactions, and without synchronized clocks, conflicts and inconsistencies may occur.
- Ordering events: Different components or nodes often perform actions or events concurrently, to make sense of these events and ensure a consistent view of the system, you need to order them accurately
- Logging and debugging states: Synchronized clocks make it easier to log events and debug issues in a distributed system. Example of OOP yeta haldim
- Coordination: schedule tasks, allocate resources and all that
- Security ni lekhe bhayo haina
Clocks, events and process states:
Take a distributed system to consist of a collection of N processes, each process executes on a single processor, and the processors do not share memory
Assume that processes cannot communicate with one another in any way except by sending messages through the network
Each process has a state , that it transforms as it executes, as each process executes it takes a series of actions, each of which is an operation that transforms ‘s state.
The sequence of events within a single process pi can be placed in a single, total ordering, which we denote by the relation between the events, e e’ if and only if the event e occurs before e’ at , now can define the history of process to be the series of events that take place within it
The OS reads the node’s hardware clock value, , scales it and adds an offset so as to produce a software clock that approximately measures real, physical time for process
Note that successive events will correspond to different timestamps only if the clock resolution - the period between updates of the clock value - is smaller than the time interval between successive events.
Clock drift
Crystal-based clocks are subject to drift, means that they count time at different rates, and so diverge. Different rates means one second for me may not be same as one second for you considering temperatures and other factors. Even one second for it in the morning may not be same as one second for me in the day.
The underlying oscillators are subject to physical variations, with the consequence that their frequencies of oscillations differ, might be extremely small, but the difference accumulated over many oscillations leads to an observable difference in the counters registered by two clocks.
Computers clocks can be synchronized to external sources of highly accurate time, most accurate physical clocks use atomic oscillators, whose drift rate is about one part in
Correctness for clocks
Common to define a hardware clock to be correct if its drift rate falls within a known bound, a value derived from one supplied by the manufacturer, such as secs/sec.
Sometimes also require our software to obey the condition but a weaker condition of monotonic may suffice, is the condition that a clock only ever advances. Can achieve monotonicity despite the fact that clock is found to be running fast.
For ex: make compiles only those source files that have been modified since they were last compiled, if a computer whose clock was running fast set its clock back after compiling a source file but before the file was changed
A hybrid correctness is sometimes applied, a clock which is not correct according to these measures is faulty.
Synchronization
In order to know at what time of day events occur at the processes in our distributed system, for accountancy purposes, it is necessary to synchronize the process’ clocks, , with an authoritative, external source of time.
External synchronization:
For a synchronization bound , and for a source of UTC time, , for and for all real times in , say that the clocks are accurate to within the bound .
And if the clocks are synchronized with one another to a known degree of accuracy, then we can measure the interval between two events occuring at different computers by appealing to their local clocks, even though they are not necessarily synchronized to an external source of time.
Internal synchronization:
For a synchronization bound , for and for all real times in , say that the clocks agree within the bound .
Note: If the system is externally synchronized with a bound D, then the same system is internally synchronized with a bound of .
Synchronous system
Simplest case between two processes in a synchronous distributed system.
Bounds are known for the drift rate of clocks, the maximum message transmission delay, and the time required to execute each step of a process.
One process sends the time on its local clock to the other in a message , in principle, the receiving process could set its clock to the time , where is the time taken to transmit m between them
Unfortunately is subject to variation and is unknown.
Let the uncertainty in the message transmission time be , so that so if the receiver sets its clock to be , then the clock skew may be as much as , since the message may in fact have taken time to arrive, similarly if it sets its clock to , the skew may again be as large as , if, however, it sets its clock to the halfway point, , then the skew is at most .
In general, the optimum bound that can be achieved on clock skew synchronizing clocks is .
Most distributed system found in practice are asynchronous: the factors leading to message delay are not bounded in their effect, and there is no upper bound max on message trasnmission delays such as Internet.
Cristian’s method for synchronizing clocks
While there is no upper bound on message transmission delays in an asynchronous system, the round-trip times for messages exchanged between pairs of processes are reasonably short.
Probabilistic, achieves synchronization only if the observed round-trip times between client and server are sufficiently short compared with required accuracy.
Suggested the use of a time server, connected to a device that receives signals from a source of UTC, to synchronized computers externally.
A process requests the time in a message , and receives the time value in a message ( is inserted in mt at the last possible point before transmission from ’s computer)
Process records the total round-trip time taken to send the request and receive the reply .
Can measure this time with reasonable accuracy if its rate of clock drift is small, for example, the round-trip time should be on the order of to milliseconds on a LAN, over which time a clock with a drift rate of seconds/second varies by at most milliseconds.
A simple estimate of the time to which should set its clock is which assumes that the elapsed time is split equally before and after placed in , normally a reasonably accurate assumption, unless the two messages are transmitted over different networks.
The earliest point at which could have placed the time in was after dispatched , the latest point at which it could have done this was before arrived at .
The time by ’s clock when the reply message arrives is therefore in the range , width of which is so the accuracy is
The Berkeley algorithm
Specially for internal synchronization for collections of computer running Berkeley UNIX.
A coordinator computer is chosen to act as the master, which periodically polls the other computers whose clocks are to be synchronized called slaves.
The slaves send back their clock values to it, master estimates their local clock by observing the round-trip times similarly to Cristian’s technique, and averages the values obtained (including its clock’s reading).
The balance of probabilities is that this average cancels out the individual clocks’ tendencies to run fast or slow.
The accuracy of the protocol depends upon a nominal maximum round-trip time between the master and the slaves, master eliminates any occasional readings associated with larger times than this maximum.
Instead of sending the updated current time back to the other computers - which would introduce further uncertainty due to the message transmission time - the master sends the amount by which each individual slave’s clock requires adjustment, can be a positive or negative value.
The Berkeley eliminates readings from faulty clocks, such clocks could have a significant adverse effect if an ordinary average was taken so instead the master takes a fault-tolerant average, i.e., a subset is chosen of clocks that do not differ from one another by more than a specified amount, and the average is taken of readings from only these clocks.
Should the master fail, then another can be elected to take over and function exactly as its predecessor.
The Network Time Protocol
Cristina’s method and Berkeley are intended primarily for use within intranets.
NTP defines an architecture for a time service and a protocol to distribute time information over the Internet.
Aims and features
-
To provide a service enabling clients across the Internet to be synchronized accurately to UTC: although large and variable message delays are encountered in Internet communication, NTP employs statistical techniques for their filtering of timing data and it discriminates between the quality of timing data from different servers.
-
To provide a reliable service that can survive lengthy losses of connectivity: there are redundant servers and redundant paths between the servers, which can reconfigure so as to continue to provide the service if one of them becomes unreachable.
-
To enable clients to re-synchronize sufficiently frequently to offset the rates of drift found in most computers: the service is designed to scale to large numbers of clients and servers.
-
To provide protection against interference with the time service, whether malicious or accidental: the time service uses authentication techniques to check that timing data originate from the claimed trusted sources.
The NTP service is provided by a network of servers located across the Internet, primary servers are connected directly to a time source such as a radio clock receiving UTC; secondary servers are synchronized, ultimately, with primary servers.
The servers are connected in a logical hierarchy called a synchronization subnet, whose levels are called strata.
Primary servers occupy stratum 1; they are at the root, stratum 2 servers are directly connected with the primary servers; stratum 3 servers are synchronized with stratum 2 servers, and so on.
The lower-level leaf servers execute in user’s workstations.
The synchronization subnet can reconfigure as servers become unreachable or failures occur, if a primary server’s UTC fails, then it can become a stratum 2 secondary server, if a secondary server’s normal source of synchronization fails or becomes unreachable, then it may synchronize with another server/
NTP servers synchronize with one another in one of three modes:
-
Multicast mode is intended for use on a high speed LAN, one or more servers periodically multi-casts the time to the servers running in other computes connected by the LAN, which set their clocks assuming a small delay, can achieve only relatively low accuracy, but ones that nonetheless are considered sufficient for many purposes
-
Procedure-call mode is similar to the operation of Cristian’s algorithm, in this mode, one server accepts request from other computers, which it processes by replying with its timestamps, is suitable where higher accuracy are required, or where mutlicast is not supported in hardware, for example, file servers on the same or a neighboring LAN that need to keep accurate timing info for file access could contact a local server in procedure call mode.
-
Symmetric mode is intended for use by the severs that supply time information in LANs, and by the higher levels of the synchronization subnet, where the highest accuracy are to be achieved, a pair of servers operating in symmetric mode exchange messages bearing timing information, which are retained as part of an association between the servers that is maintained in order to improve the accuracy of their synchronization over time.
In all modes, messages are delivered unreliably, using the standard UDP Internet transport protocol.
In procedure-call mode and symmetric mode, processes exchange pairs of messages, each message bears timestamps of recent message events:
- the local times when the previous NTP message between the pair was sent and received,
- the local time when the current message was transmitted.
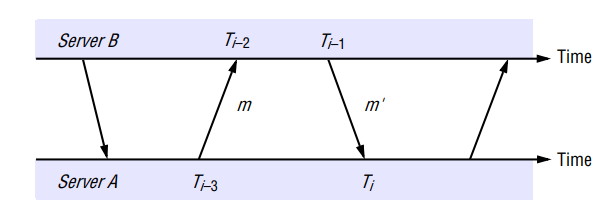
There can be a non-negligible delay between the arrival of one message and the dispatch of the next, also messages may be lost, but timestamps carried by each message are nonetheless valid.
For each pair of messages sent between two servers the NTP calculates an offset , which is an estimate of the actual offset between the two clocks, and a delay , which is the total transmission time for the two messages.
If the true offset of the clock at B relative to that at A is , and if the actual transmission time for and are and respectively then,
Prediction of offset: Also, T_{i-2} = T_{i-3} + t + o$$$$T_i+o = T_{i-1} + t'This leads to
Using the fact that , it can be shown that , thus is an estimate of the offset and is a measure of the accuracy of this estimate.
NTP servers apply a data filtering algorithm to successive pairs , which estimates the offset and calculates the quality of this estimate as a statistical quantity called filter dispersion, relatively high of which represents relatively unreliable data.
The eight most recent pairs are retained, the value of that corresponds to the minimum value is chosen to estimate .
The value of the offset derived from communication with a single source is not necessarily used by itself to control the local clock.
In general, an NTP server engages in message exchanges with several of its peers, in addition to data filtering applied to exchanges with each single peer, NTP applies a peer-selection algorithm, which examines the values obtained from exchanges with each of several peers, looking for relatively unreliable values.
Peers with lower stratum numbers are more favoured than those in higher strata because they are closer to the primary time sources.
NTP employs a phase lock look model, which modifies the local clock’s update frequency in accordance with observation of its drift rate.
For ex: if a clock is discovered always to gain time at the rate of, four seconds per hour, then its frequency can be reduced slightly in software or hardware to compensate this
The clock’s drift in the intervals between synchronization is thus reduced, Mills quites synchronization accuracy on the order of tens of millions over the Internet paths, and one milliseconds on LANs.
Logical clocks
A logical clock is a mechanism that assigns unique timestamps to events, faciliating event ordering without relying on synchronized physical clocks.
Since we cannot synchronize clocks across a distributed system, cannot in general use physical time to find out the order of any arbitrary pair of events occurring within it.
Can apply physical causality in distributed systems to order some of the vents that occur at different processes.
Based on two points:
- If two events occurred at the same process , then they occurred in the order in which observes them.
- Whenever a message is sent between process, the event of sending the message occurred before the event of receiving the message.
Can define the happened-before relation, denoted by → as follows:
- HB1: if there exists a process , then
- HB2: For any message ,
- HB3: if , and are events such that and then
Thus, if and are events, and if then we can find a series of events occurring at one or more process such that and , and for that either HB1 or HB2 applies between and , that is, either they occur in successively at the same process, or there is a message m such that and .
Note: Not all events are related by the relation → as they occur at different processes, and there is no chain of messages intervening between them, say that the events that are not ordered by → are concurrent and write this , since no network messages were sent between the issuing processes, cannot model this type of relationship.
Lamport
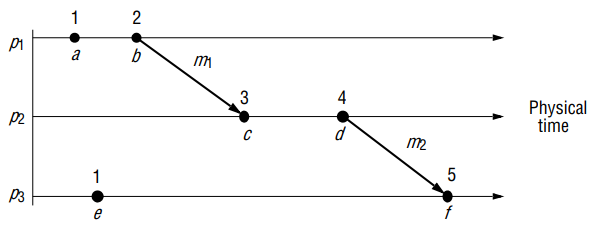
Lamport invented a simple mechanism by which the happened-before ordering can be captured numerically, called a logical clock.
A Lamport logical clock is a monotonically increasing software counter, whose value need bear no particular relationship to any physical clock.
Each process keeps its own logical clock , which it uses to apply so-called Lamport timestamps to events.
To capture the happened-before relation →, processes update their logical clocks and transmit the values of their logical clocks in messages as follows
Call timestamp of event at by and the timestamp of event at whatever process it occurred at by
- is incremented before each event is issued at process
-
- When a process sends a message , it piggybacks on the value
- On receiving , a process computes and then applies before timestamping the event
Can be shown by induction that on the length of any sequence of events relating two events and , that .
Not the other way around though?
Totally ordered logical clocks
Some pairs of distinct events, generated by different processes, have numerically identical Lamport timestamps.
However can create a total order on the set of events - that is, one for which all pairs of distinct events are ordered - by taking into account the identifiers of the process at which events occur.
If is an event occurring at with local timestamp , and e’ is an event occurring at with local timestamp , we define the global time stamps for these events to be and respectively.
And define if and only if either or and , which has no physical significance because process identifiers are arbitrary.
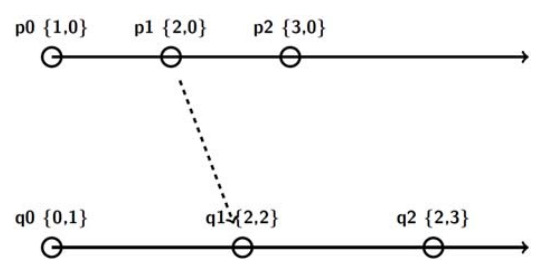
Vector clocks:
Mattern and Fidge developed vector clocks to overcome the shortcoming of Lamport’s clocks: the fact that from cannot conclude that
A vector clock for a system of processes is an array of integers, each process keeps its own vector clock, , which uses to timestamp local events.
Like Lamport timestamps, processes piggyback vector timestamps on the messages they send to one another, and there are simple rules for updating the clocks
- Initially, , for
- Just before timestamps an event it sets
- includes the value in every message it sends.
- When receives a timestamp in a message, it sets , for , taking the component-wise maximum of two vector timestamps in this way is known as a merge operation.
For a vector clock, , is the number of events that has timestamps, and () is the number of events that have occurred at that have potentially affected , process may have timestamped more events by this point, but no information has flowed to about them in messages as yet.
Comparison of vector timestamps as
- iff for
- iff for
Vector timestamps have the disadvantage, compared with Lamport timestamps, of takng up an amount of storage and message payload that is proportional to , the number of processes.
Global states
Time to examine the problem of finding out whether a particular property is true of a distributed system as it executes.
- Distributed garbage collection:
- Distributed deadlock detection:
- Distributed termination detection:
- Distributed debugging:
If all processes had perfectly synchronized clocks, then we could agree on a time at which each process would record its state - the result would be an actual global state of the system.
How to ascertain a global state?
A cut of the system’s execution is a union of all processes’ global histories up to a specific event in each history.
A cut is consistent if, for each event it contains, it also contains all the events that happened-before that event. The global state consist of states of each processes immediately after the last event processed by in the cut .
A consistent global state is one that corresponds to a consistent cut, which is a possible state without contradiction.
Can characterize the execution of a distributed system as a series of transitions between the global states of the system.
In each transition, precisely one event occurs at some single process in the system, if two events happened simultaneously, may nonetheless deem them to have occurred in a definite order - say, ordered according to process identifiers.
A run is a total ordering of all the events in a global history that is consistent with each local history’s ordering.
A linearization or consistent run is an ordering of the events in a global history that describes the transitions between consistent global states.
Sometimes may alter the ordering of concurrent events within a linearization, and derive a run that still passes through only consistent global states, for example, if two successive events in a linearization are the receipt of messages by two processes, then may swap the order of these two events.
If we can collect all events and known the happened before order, then we can construct all possible linearizations.
A Lamport diagram with vector clocks
Linearizations:
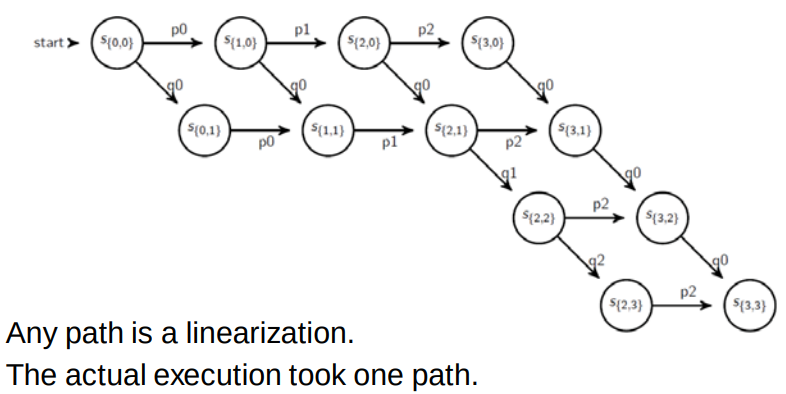
We know for sure that the actual execution took one of these paths so can we say something about the execution even though we do not exactly know which path was taken?
-
Possibly True: if a predicate is true in a consistent global state of the lattice then it is possibly true in the execution.
-
Definitely True: if we cannot find a path from the initial state to the final state without reaching a state for which a predicate is true then the predicate is definitely true during the execution.
Detection a condition such as deadlock or termination amounts to evaluating a global state predicate, which is a function that maps from the set of a global states of processes in the system to {True, False}
Useful characteristics of deadlock or termination predicates it that they are all stable: once the system enters a state in which the predicate is True, it remains True in all future states reachable from that state.
By contrast, when we monitor or debug an application we are often interested in non-stable predicates.
Let’s capture a possible state:
Capture a consistent global state that was possibly true in the execution, if a stable predicate is true for this state - then it is true in the actual execution
Snapshot algorithm of Chandy and Lamport
The goal of the algorithm is to record a set of process and channel states for a set of processes such that, even though the combination of recorded states may never have occurred at the same time, the recorded global state is consistent.
The algorithm records state locally at processes, it does not give a method for gathering the global state at one site, an obvious method for gathering the state is for all processes to send the state they recorded to a designated collector process.
Assume that
- Neither channels not processes fail - communication is reliable so that every message sent is eventually received intact, exactly once.
- Channels are unidirectional and provide FIFO-ordered message delivery.
- The graph of processes and channels is strongly connected, there is a path between any two processes.
- Any process may initiate a global snapshot at any time.
- The process may continue their execution and send and receive normal messages while the snapshot takes place.
Essential idea
Each process records its state and also, for each channel, any messages that arrived after it recorded its state and before the sender recorded its own state, which allows to record the states of processes at different times and to account for the differentials between process states in terms of messages transmitted but not yet received.
If process has sent a message to process , but has not received it, then we account for as belonging to the state of the channel between them.
The algorithm proceeds through use of special marker messages, which are distinct from any other messages the processes send and which processes may send and receive while they proceed with their normal execution.
The marker has a dual role: as a prompt for the receiver to save its own state, if it has not already done so; and as a means of determining which messages to include in the channel state.
The algorithm is defined through two rules, the marker receiving rule and the marker sending rule:
The initiator process: Records its own state. Sends a marker message out on all its outgoing channels. Starts recording the messages it receives on all its incoming channels.
When process receives a marker message on : If it is the first marker has seen (sent or received): records its state. marks channel as empty. sends a marker out on all its outgoing channels. starts recording on all incoming channel except . Otherwise: stops recording on .
Several processes may initiate recording concurrently in this way as long as the markers they use can be distinguished.
Evaluate possibly and definitely
Need to make useful statements about whether a transitory state - as opposed to a stable state - occured in an actual execution (bhannale Chandy Lamport le ta possibly ko lagi matra bhanxa ni ta)
-
An example where the safety condition required that for which is to be met even though a process may change the value of its variable at any time.
-
Another example is a distributed system controlling a system of pipes in a factory where we are interested in whether all the valves were open at same time.
In these examples, we cannot in general observer the values of the variables or the states simultaneously,. The challenge is to monitor the system’s execution over time - to capture trace information rather than a single snapshot - so that we can establish post hoc whether the required safety was or may have been violated.
The Marzulo and Neiger algorithm is centralized in which observed processes send their states to a process called a monitor, which assembles globally consistent states from what it receives, which lie outside the system, observing its execution.
Our aim is to determine cases where a given global state perdicate was definitely at some point in the execution we observed, and cases it was possibly .
Define the notions of possibly and definitely
- possibly: The statement possibly means that there is a consistent global state through which a linearization of passes such that is
- definitely: The statement definitely phi means that for all linearization of , there is a consistent global state through which passes such that is /
When we use Chandy and Lamport’s snapshot algorithm and obtain the global state , we may assert possibly if happens to be .
The observed processes send their initial state to the monitor initially, and thereafter from time to time, in state messages. The monitor records the state messages from each process in separate queue for each . The activity of preparing and sending state messages may delay the normal execution of the observed processes, but it does not otherwise interfere with it. There is no need to send the state except initially and when it changes.
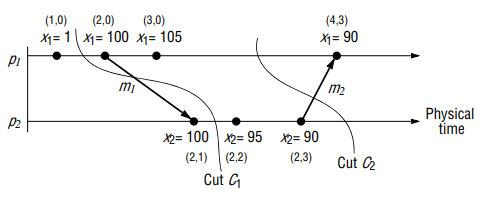
For example, considering two processes and with variables and respectively. The event shown on the timelines with vector timestamps are adjustments to the values of the two variables. Initially . The requirement is .
Whenever one of the processes or adjusts the value of its variable, it sends the value in a state message to the monitor. It keeps the state messages in the per-process queue for analysis. If the monitor were to use values from the inconsistent cut then it would find breaking the constraint.
In order that the monitor can distinguish consistent global states from inconsistent global states, the observed processes enclose their vector clock values with their state messages. Each queue is kept in sending order, which can immediately be established by examining the component of the vector timestamps. s. Of course, the monitor may deduce nothing about the ordering of states sent by different processes from their arrival order, because of variable message latencies. It must instead examine the vector timestamps of the state messages.
Let be a global state drawn from the state messages that the monitor has received. Let be a the vector timestamp of the state received from . Then it can be shown that is a consistent global state if and only if:
- Evaluate possibly for global history of of processes: …
- Evaluate definitely for global history of of processes: …