Maintenance of copies of data at multiple computers. Replication is a key to the effectiveness of distributed systems in that it can provide enhanced performance, high availability and fault tolerance. With a large number of nodes, the probability that at least one node will malfunction in a parallel system is significantly greater than in a single-node system. A poorly designed parallel system will stop functioning if any node fails. A
Replication is used widely. For example, the caching of resources from web servers in browsers and web proxy servers is a form of replication, since the data held in caches and at servers are replicas of one another. The DNS naming service maintains copies of name-to-attribute mappings for computers and is relied on for day-to-day access to services across the Internet.
Replication is a technique for enhancing services. The motivation for replication include:
-
Performance enhancement: Browsers and proxy servers cache copies of web resources to avoid the latency of fetching resources from the originating server. Furthermore, data are sometimes replicated transparently between originating servers in the same domain. The workload is shared between the servers by binding all the server IP addresses to the site’s DNS name. A DNS lookup of it results in one of the several server’s IP addresses being returned, in a round-robin fashion. Replication of changing data is trivial: it increases performance with little cost to the system. Replication of changing data, such as that of Web, incurs overheads in the form of protocols designed to ensure that clients receive up-to-date data.
-
Increased availability: Users require services to be highly available. That is, the proportion of time for which a service is accessible with reasonable response times should be close to 100%. Apart from delays due to pessimistic concurrency control conflicts, the factors that are relevant to high availability are:
- server failures: If data are replicated at two or more failure-independent servers, then client software may be able to access data at an alternative server should the default server fail or become unreachable. That is, the percentage of time during which the service is available can be enhanced by replicating server data. If each of n servers has an independent probability of failing or becoming unreachable, then the availability of an object stored at each of these servers is .
- network partitions and disconnected operation: Mobile users may deliberately disconnect their computers or become unintentionally disconnected from a wireless network as they move around. In order to be able to work in these circumstances – so-called disconnected working or disconnected operation – the user will often prepare by copying heavily used data, such as the contents of a shared diary, from their usual environment to the laptop. But there is often a trade-off to availability during such a period of disconnection: when the user consults or updates the diary, they risk reading data that someone else has altered in the meantime.
-
Fault tolerance: Highly available data is not necessarily strictly correct data. It may be out of data, for example: or two users on opposite sides of a network partition may make updates that conflict and need to be resolved. A fault-tolerant service, by contrast, always guarantees strictly correct behavior despite a certain umber and type of faults. The correctness concerns the freshness of data supplied to the client and the effects of the client’s operations upon the data. The same basic technique used for high availability – that of replicating data and functionality between computers – is also applicable for achieving fault tolerance. If up to of servers crash, then in principle at least one remains to supply the service. And if up to f servers can exhibit Byzantine failures, then in principle a group of 2f + 1 servers can provide a correct service, by having the correct servers outvote the failed servers (who may supply spurious values).
A common requirement when data are replicated is for replication transparency. That is, clients should not normally have to be aware that multiple physical copies of data exist.
Fault-tolerant
If a system is to be fault tolerant, the best it can do is try to hide the occurrence of failures from other processes. The key technique for masking faults is to use redundancy. Three kinds are possible:
- information redundancy,
- time redundancy, and
- physical redundancy.
With information redundancy, extra bits are added to allow recovery from garbled bits. For example, a Hamming code can be added to transmitted data to recover from noise on the transmission line.
With time redundancy, an action is performed, and then. if need be, it is performed again.
With physical redundancy, extra equipment or processes are added to make it possible for the system as a whole to tolerate the loss or malfunctioning of some components. Physical redundancy can thus be done either in hardware or in software. For example, extra processes can be added to the system so that if a small number of them crash, the system can still function correctly.
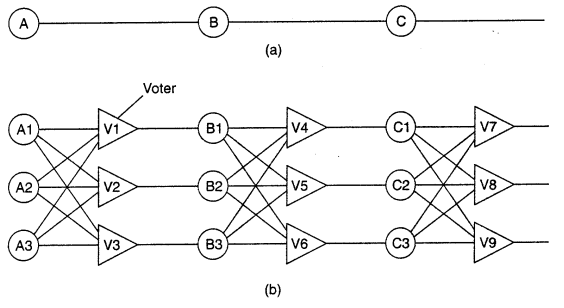
Physical redundancy is a well-known technique for providing fault tolerance. In here, each device is replicated three times. Following each stage in the circuit is a triplicated voter. Each voter is a circuit that has three inputs and one output. If two or three of the inputs are the same, the output is equal to that input. If all three inputs are different, the output is undefined.
Even though only using a single voter brings a single point of failure - most TMR systems do not use triplicated voters.
This kind of design is known as TMR (Triple Modular Redundancy).
Process Resilience
The key approach to tolerating a faulty process is to organize several identical processes into a group. The key property that all groupshave is that when a message is sent to the group itself, all members of the group receive it. In this way, if one process in a group fails, hopefully some other process can take over for it.
Process groups may be dynamic. New groups can be created and old groups can be destroyed. A process can join a group or leave one during system operation. A process can be a member of several groups at the same time. Consequently, mechanisms are needed for managing groups and group membership.
The purpose of introducing groups is to allow processes to deal with collections of processes as a single abstraction. Thus a process can send a message to a group of servers without having to know who they are or how many there are or where they are, which may change from one call to the next.
An important distinction between different groups has to do with their internal structure. In some groups, all the processes are equal. No one is boss and all decisions are made collectively.
In other groups, some kind of hierarchy exists. For example, one process is the coordinator and all the others are workers. In this model, when a request for work is generated, either by an external client or by one of the workers, it is sent to the coordinator. The coordinator then decides which worker is best suited to carry it out, and forwards it there.
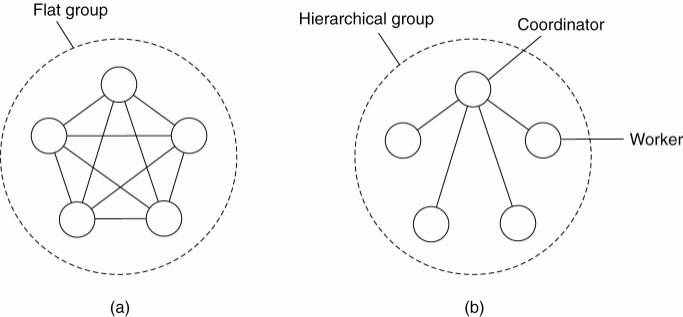
Each of these organizations has its own advantages and disadvantages. The flat group is symmetrical and has no single point of failure. If one of the processes crashes, the group simply becomes smaller, but can otherwise continue. A disadvantage is that decision making is more complicated. For example, to decide anything, a vote often has to be taken, incurring some delay and overhead.
Replication as a scaling technique
Scalability issues generally appear in the form of performance problems. Placing copies of data close to the processes using them can improve performance through reduction of access time and thus solve scalability problems.
A possible trade-off that needs to be made is that keeping copies up to date may require more network bandwidth.
Consider a process P that accesses a local replica N times per second, whereas the replica itself is updated M times per second. Assume that an update completely refreshes the previous version of the local replica. If N < M, that is, the access-toupdate ratio is very low, we have the situation where many updated versions of the local replica will never be accessed by P, rendering the network communication for those versions useless.
In this case, it may have been better not to install a local replica close to P, or to apply a different strategy for updating the replica.
A more serious problem, however, is that keeping multiple copies consistent may itself be subject to serious scalability problems.
Intuitively, a collection of copies is consistent when the copies are always the same. This means that a read operation performed at any copy will always return the same result. Consequently, when an update operation is performed on one copy, the update should be propagated to all copies before a subsequent operation takes place, no matter at which copy that operation is initiated or performed. This type of consistency is sometimes informally referred to as tight consistency or synchronous replication.
The key idea is that an update is performed at all copies as a single atomic operation, or transaction, we need to synchronize all replicas. this means that all replicas first need to reach agreement on when exactly an update is to be performed locally.
For example, replicas may need to decide on a global ordering of operations using Lamport timestamps, or let a coordinator assign such an order.
We are now faced with a dilemma. On the one hand, scalability problems can be alleviated by applying replication and caching, leading to improved performance. On the other hand, to keep all copies consistent generally requires global synchronization, which is inherently costly in terms of performance.
Consistency Models
Consistency models in distributed systems refer to the guarantees provided by the system about the order in which operations appear to occur to clients. Specifically, it determines how data is accessed and updated across multiple nodes in a distributed system, and how these updates are made available to clients.
Traditionally, consistency has been discussed in the context of read and write operations on shared data, available means of shared memory, a shared database or a file system. We use the broader term data store. A data store may be physically distributed across multiple machines.
All models attempt to return the results of the last write for a read operation while differ in how last write is determined or defined. In particular, each process that can access data from the store is assumed to have a local (or nearby) copy available of the entire store.
Write operations are propagated to the other copies. A data operation is classified as a write operation when it changes the data, and is otherwise classified as a read operation.
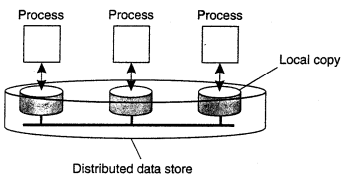
A consistency model is essentially a contract between processes and the data store. It says that if processes agree to obey certain.rules, the store promises to work correctly. Normally, a process that performs a read operation on a data item, expects the operation to return a value that shows the results of the last write operation on that data.
In the absence of a global clock, it is difficult to define precisely which write operation is the last one. As an alternative, we need to provide other definitions, leading to a range of consistency models. Each model effectively restricts the values that a read operation on a data item can return.
Strict consistency
…
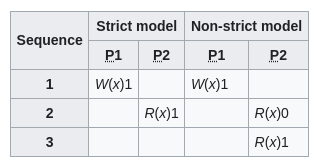
Sequential consistency
An important data-centric consistency model, which was first defined by Lamport in the context of shared memory for multiprocessor systems. In general, a data store is said to be sequentially consistent if it satisfies the following condition:
The result of an execution is the same as if the read and write operations by all processes on the data store were executed in same sequential order and the operations of each individual process appear in this sequence in the order specified by its program.
What this definition means is that when processes run concurrently on possibly different machines, any valid interleaving of read and write operations is acceptable behavior, but all processes see the same interleaving of the operations.
Note that nothing is said about time; that is, there is no reference to the most recent write operation on a data item. Note that in this context, a process sees writes from all processes but only its own reads.

Consider four processes operating on the same data item . In process first performs , process performs a write operation, by setting the value to b. However both processes and first read value b, and later value a. In other words, the write operation of process appears to have taken place before .
In contrast, b) violates sequential consistency because not all processes see the same interleaving of write operations. In particular, to process , it appears as if the data item has been first changed to , and later to . On the other hand, will conclude the final value is .
Causal consistency
The causal consistency represents a weakening of the sequential consistency in that it makes a distinction between events that are potentially causally related and those that are not. If event b is caused or influenced by an earlier event a, causality requires that everyone else first see a, then see b.
For a data store to be considered causally consistent, it is necessary that the store obeys the following condition:
Writes that are potentially causally related must be seen by all processes in same order. Concurrent writes may be seen in different order on different machines.
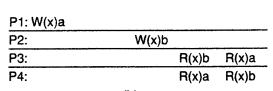
W(x)a and W(x)b are concurrent writes. A causally-consistent store does not require concurrent writes to be globally ordered, so is correct. It reflects the situation that would not be acceptable for a sequentially consistent store.
Implementing causal consistency requires keeping track of which processes have seen which writes. It effectively means that a dependency graph of which operation is dependent on which other operations must be constructed and maintained.
Eventual consistency
Consider a worldwide naming system such as DNS. The DNS name space is partitioned into domains, where each domain is assigned to a naming authority, which acts as owner of that domain. The only situation that needs to handled are read-write conflicts, in which one process wants to update a data item while another is concurrently attempting to read that item. As it turns out it is often possible to propagate an update in a lazy fashion, meaning that a reading process will see an update only after some time has passed since the update took place.
These examples can be viewed as replicas that tolerate a relatively high degree of inconsistency. They have in common that if no updates took place for a long time all replicas will gradually become consistent. This form of consistency is called eventually consistency.
Content Replication and Placement
Passive replication
In the passive or primary-backup model of replication for fault tolerance, there is at any one time a single primary replica manager and one or more secondary replica managers – backups or slaves. In the pure form of the model, front ends communicate only with the primary replica manager to obtain the service. In a variation of the model presented here, clients may be able to submit read requests to the backups, thus offloading work from the primary. The guarantee of linearizability is thereby lost, but the clients receive a sequentially consistent service.
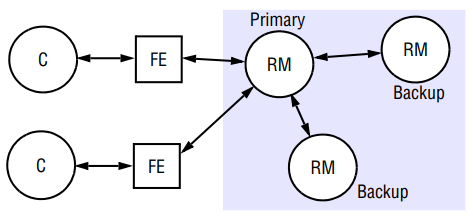
The primary replica manager executes the operations and sends copies of the updated data to the backups. If the primary fails, one of the backups is promoted to act as the primary.
The sequence of events when a client requests an operation to be performed is as follows:
- Request: The front end issues the request, containing a unique identifier, to the primary replica manager.
- Coordination: The primary takes each request atomically, in the order in which it receives it. It checks the unique identifier, in case it has already executed the request, and if so it simply re-sends the response.
- Execution: The primary executes the request and stores the response.
- Agreement: If the request is an update, then the primary sends the updated state, the response and the unique identifier to all the backups. The backups send an acknowledgement.
- Response: The primary responds to the front end, which hands the response back to the client.
This system obviously implements linearizability if the primary is correct, since the primary sequences all the operations upon the shared objects. If the primary fails, then the system retains linearizability if a single backup becomes the new primary and if the new system configuration takes over exactly where the last left off.
To survive up to process crashes, a passive replication system requires replica managers, such a system cannot tolerate Byzantine faults. The front end requires little functionality to achieve fault tolerance. It just needs to be able to look up the new primary when the current primary does not respond.
Passive replication has the disadvantage of providing relatively large overheads.
The Sun Network Information Service (NIS, formerly Yellow Pages) uses passive replication to achieve high availability and good performance, although with weaker guarantees than sequential consistency.
Active replication
In the active model of replication for fault tolerance, the replica managers are state machines that play equivalent roles and are organized as a group. Front ends multicast their requests to the group of replica managers and all the replica managers process the request independently but identically and reply.
If any replica manager, this need have no impact upon the performance of the service, since the remaining replica managers continue to respond in the normal way. We shall see that active replication can tolerate Byzantine failures, because the front end can collect and compare the replies it receives.
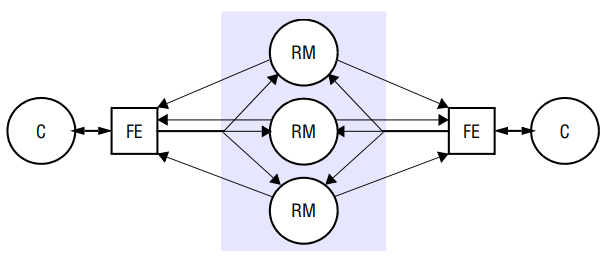
Under active replication, the sequence of events when a client requests an operation to be performed is as follows:
- Request: The front end attaches a unique identifier to the request and multicasts it to the group of replica managers, using a totally ordered, reliable, multicast primitive. The front end is assumed to fail by crashing at worst. It does not issue the next request until it has received a response.
- Coordination: The group communication system delivers the request to every correct replica manager in the same total order.
- Execution: The replica manager executes the request. Since they are state machines and since requests are delivered in the same total order, correct replica managers all across the request identically. The response contains the client’s unique request identifier.
- Agreement: No agreement phase is needed, because of the multicast delivery semantics.
- Response: Each replica manager sends its response to the front end. The number of replies that the front end collects depends upon the failure assumption and the multicast algorithm. If, for example, the goal is to tolerate only crash failures and the multicast satisfies uniform agreement and ordering properties, then the front end passes the first response to arrive back to the client and discards the rest (it can distinguish these from responses to other requests by examining the identifier in the response).
This system achieves sequential consistency. All correct replica managers process the same sequence of requests. The reliability of the multicast ensures that every correct replica manager processes the same set of requests and the total order ensures that they process them in the same order. . Such a multicast can be implemented using Lamport’s logical clocks.
The active replication system does not achieve linearizability. This is because the total order in which the replica managers process requests is not necessarily the same as the real-time order in which the clients made their requests.
Case Study: The Gossip Architecture
Ladin et al. developed what we call the gossip architecture as a framework for implementing highly available services by replicating data close to the points where groups of clients need it. The name reflects the fact that the replica managers exchange gossip messages periodically in order to convey the updates they have each received from clients.
A key feature is that front ends send queries and updates to any replica manager they choose, provided it is available and can provide reasonable response times. The system makes two guarantees, even though replica managers may be temporarily unable to communicate with one another:
-
Each client obtains a consistent service over time: In answer to a query, replica managers only ever provide a client with data that reflects at least the updates that the client has observed so far. This is even though clients may communicate with different replica managers at different times, and therefore could in principle communicate with a replica manager that is less advanced than one they used before.
-
Relaxed consistency between replicas: All replica managers eventually receive all updates and they apply updates with ordering guarantees that make the replicas similar to suit the needs of the application. It is important to realize that while the gossip architecture can be used to achieve sequential consistency, it is primarily intended to deliver weaker consistency guarantees. Two clients may observe different replicas even though the replicas include the same set of updates, and a client may observe stale data.
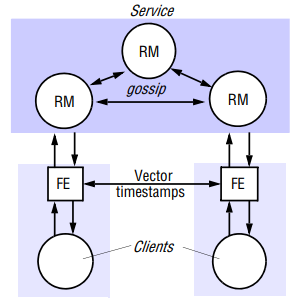
An outline of how a gossip processes queries and update operations is as follows:
- Request: The front end normally sends requests to only a single replica manager at a time. However, a front end will communicate with a different replica manager when the one it normally uses fails or becomes unreachable, and it may try one or more others if the normal manager is heavily loaded. Front ends, and thus clients, may be blocked on query operations. The default arrangement for update operations, on the other hand, is to return to the client as soon as the operation has been passed to the front end; the front end then propagates the operation in the background. Alternatively, for increased reliabiility clients may be prevented from continuing the update has beed delivered to replica managers, ensuring that it will be delivered everywhere despite failures.
- Update response: If the request is an update, then the replica manager replies as soon as it has received the updat.
- Coordination: The replica manager that recevies does not process it until it can apply the request according to the required ordering constraints.
- Execution: The replica manager executes the request.
- Query response: If the request is a query, then the replica manager replies at this point.
- Agreement: gossip messages, lazily