Refers to a transaction that accesses objects managed by multiple servers. When a distributed transaction comes to an end, the atomicity property of transactions requires that either all of the servers involved commit the transaction or all of them abort the transaction.
To achieve this, one of the servers takes on a coordinator role, which involves ensuring the same outcome at all of the servers. The protocols such as two phase commit allows the servers to communicate with one another to reach a join decision as to whether to commit or abort.
Each server applies local concurrency control to its own objects, which ensures that transactions are serialized globally. How this is achieved varies depending upon whether locking, timestamp ordering or optimistic concurrency control is in use.
Failure models for transactions
- Writes to permanent storage may fail, either by writing nothing or by writing a wrong value - for example, writing to the wrong block is a disaster. File storage may also decay. Reads from permanent storage can detect when a block of data is bad.
- Servers may crash occasionally, when a crashed server is replaced by a new process, its volatile memory is first set to a state in which it knows none of the objects from before the crash.
- There may be an arbitrary delay before a message arrives. A message may be lost, duplicated or corrupted. The recipient can detect corrupted messages during a checksum.
The fault model for permanent storage, processors and communications was used to design a stable system whose components can survive any single fault and present a simple failure model. Stable storage provided an atomic write operation in the presence of a single fault of the write operation or a crash failure of the process. This was achieved by replicating each block on two disk blocks. A stable processor used stable storage to enable it to recover its objects after a crash. Communication errors were masked by using a reliable remote procedure calling mechanism.
Middleware transactions
Transactions can be provided as part of middleware, for example, CORBA provides the specification for an Object Transaction Service with IDL interfaces allowing clients’ transactions to include multiple objects at multiple servers.
The client is provided with operations to specify the beginning and end of a transaction.
The client maintains a context for each transaction, which it propagates with each operation in that transaction.
In CORBA, transactional objects are invoked within the scope of a transaction and generally have some persistent store associated with them.
Nested transactions
Nested transactions allow transactions to be composed of other transactions, thus, several transactions may be started from within a transaction, allowing transactions to be regarded as modules that can be composed as required.
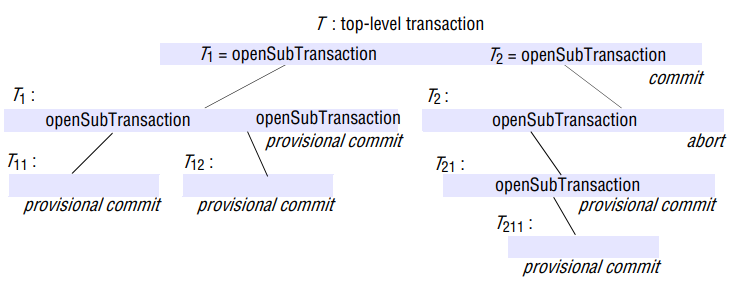
The outermost transaction is a set of nested transaction is called the top-level transaction.
Transactions other than top-level transaction are called subtransactions.
A subtransaction appears atomic to its parent with respect to transaction facilities and to concurrent access.
Subtransactions at the same level, such as and , can run concurrently, but their access to common objects is serialized - for example, by locking scheme.
Each subtransaction can fail independently of its parent and of the other subtransactions. When a subtransaction aborts, the parent transaction can sometimes choose an alternative subtransaction to complete its task.
For example, a transaction to deliver a mail message to a list of recipients could be structure as a set of subtransactions, each of which delivers the message to one of the recipients. If one or more of the subtransactions fails, the parent transaction could record the fact and then commit, with the result that all the success child transactions commit. It could then start another transaction to attempt to redeliver the messages that were not sent the first time.
Rules for committing of nested transactions are subtle:
- When a subtransaction completes, it makes an independent decision either to commit provisionally or to abort. The decision to abort is final.
- A transaction may commit or abort only after its child transactions have completed (committed provisionally).
- When a parent aborts, all of its subtransactions are aborted.
- If the top-level transaction commits, then all of the subtransactions that have provisionally committed can commit too, provided that none of their ancestors has aborted.
Advantages
- Subtransactions at one level may run concurrently with other subtransactions at the same level in the hierarchy. This allows additional concurrency in a transaction. When subtransactions run in different servers, they can work in parallel
- Subtransactions can commit or abort independently, in comparison with a single transaction, a set of nested subtransactions is potentially more robust.
The CORBA supports both flat and nested transactions. Nested transactions are particularly useful in distributed system because child transactions may be run concurrently in different servers.
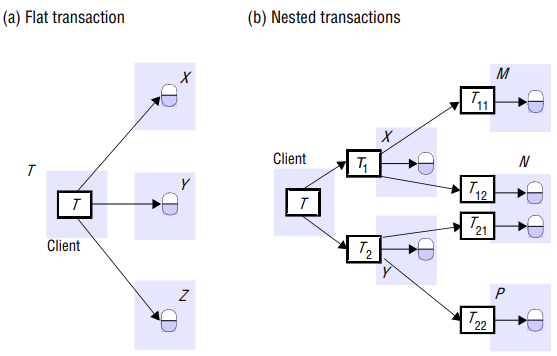
A client transaction becomes distributed if it invokes operations in several different servers. In a flat transaction, a client makes requests to more than one server.
For example, a) transaction T is a flat that invokes operations on objects in servers X, Y and Z. A flat client transaction completes each of its requests before going on to the next one. Therefore, each transaction accesses servers’ objects sequentially.
In a nested transaction, the top-level transaction can open subtransactions, and each transaction can open further subtransactions down to any depth of nesting. b) shows a client transaction that opens two subtransaction T1 and T2 which access objects at servers X and Y. They open further T11, T12, T21 and T22, which access objects at servers M, N and P. In the nested case, subtransactions at the same level can run concurrently, so T1 and T2 are concurrent, and they invoke objects in different servers, they can run in parallel.
The coordinator of a distributed transaction
Servers that execute requests as part of a distributed transaction need to be able to communicate with one another to coordinate their actions when the transaction commits. A client starts a transaction by sending an openTransaction request to a coordinator in any server.
The coordinator that opened the transaction becomes the coordinator for the distributed transaction and at the end is responsible for committing or aborting it. Each of the servers that manages an object accessed by a transaction is a participant in the transaction and provides an object we call the participant. Each participant is responsible for keeping track of all of the recoverable objects at that server that are involved, in the transaction.
The coordinator that is contacted returns the resulting transaction identifier (TID) to the client. Transaction identifiers for distributed transactions must be unique within a distributed system. A simple way to achieve this is for a TID to contain two parts: the identifier (for example, an IP address) of the server that created it and a number unique to the server.
Atomic commit protocols
The atomicity property of transactions requires that when a distributed transaction comes to an end, either all of its operations are carried out or none of them. In the case of a distributed transaction, the client requested operations at more than one server.
A transaction comes to an end when the client requests that it be committed or aborted. A simple way to complete the transaction in an atomic manner is for the coordinator to communicate the commit or abort request to all of the participants in the transaction and to keep on repeating the request until all of them have acknowledged that they have carried it out. This is an example of a one phase atomic commit protocol.
This simple one-phase atomic commit protocol is inadequate, though, because it does not allow a server to make a unilateral decision to abort a transaction when the client requests a commit.
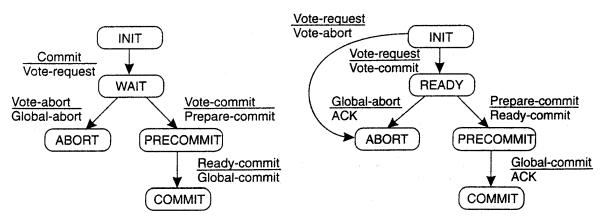
Two-phase commit protocol
The two-phase commit protocol is designed to allow any participant to abort its part of a transaction. Due to the requirement for atomicity, if one part of a transaction is aborted, then the whole transaction must be aborted.
-
In the first phase of the protocol, each participant votes for the transaction to be committed or aborted. Once a participant has voted to commit a transaction, it is not allowed to abort it. Therefore, before a participant votes to commit a transaction, it must ensure that it will eventually be able to carry out its part of the commit protocol, even if it fails and is replaced in the interim. A participant in a transaction is said to be in a prepared state for a transaction if it will eventually be able to commit it. To make sure of this, each participant saves in permanent storage all of the objects that it has altered in the transaction, together with its status – prepared.
-
In the second phase of the protocol, every participant in the transaction carries out the joint decision. If any one participant votes to abort, then the decision must be to abort the transaction. If all the participants vote to commit, then the decision is to commit the transaction.
The problem is to ensure that all of the participants vote and that they all reach the same decision. This is fairly simple if no errors occur, but the protocol must work correctly even when some of the servers fail, messages are lost or servers are temporarily unable to communicate with one another.
During the progress of a transaction, there is no communication between the coordinator and the participants apart from the participants informing the coordinator when they join the transaction. A client’s request to commit or abort a transaction is directed to the coordinator. If the client requests abortTransaction, or if the transaction is aborted by one of the participants, the coordinator informs all participants immediately.
It is when the client asks the coordinator to commit the transaction that the two-phase commit protocol comes into use.
Phase 1 (voting phase): 1. The coordinator sends a canCommit? request to each of the participants in the transaction. 2. When a transaction receives canCommit? request it replies with its vote, Yes or No, to the coordinator. Before voting Yes, it prepares to commit by saving objects in permanent storage. If the vote is No, the participant aborts immediately.
Phase 2 (completion according to outcome of vote): 3. The coordinator collects the votes (including its own). If there are no failures and all votes are Yes, the coordinator decides to commit the transaction and sends a doCommit request to each of the participants Otherwise, the coordinator decides to abort the transaction and sends doAbort requests to all participants that voted Yes. 4. Participants that voted Yes are waiting for a doCommit or doAbort request from the coordinator. When a participant receives one of these messages it acts accordingly, and, in the case of commit, makes a haveCommitted call as confirmation to the coordinator.
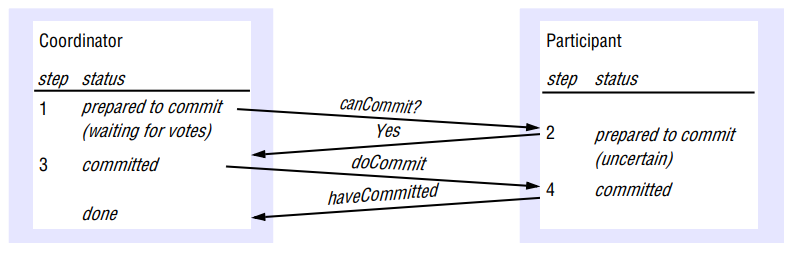
There are various stages in the protocol at which the coordinator or a participant cannot progress its part of the protocol until it receives another request or reply from one of the others.
Consider a situation where a participant has voted Yes and is waiting for the coordinator to report on the outcome of the vote by telling it to commit or abort the transaction. Such a participant is uncertain of the outcome and cannot proceed any further until it gets the outcome of the vote from the coordinator. The participant cannot decide unilaterally what to do next, and meanwhile the objects used by its transaction cannot be released for use by other transactions.
The participant can make a getDecision request to the coordinator to determine the outcome of the transaction. If the coordinator has failed, the participant will not be able to get the decision until the coordinator is replaced, which can result in extensive delays for participants in the uncertain state.
Provided that all goes well, the two-phase commit protocol involving N participants can be completed with N canCommit messages and replies, followed by doCommit messages. That is, the cost in messages is proportional to 3N.
FSM for coordinator and participant in 2PC:
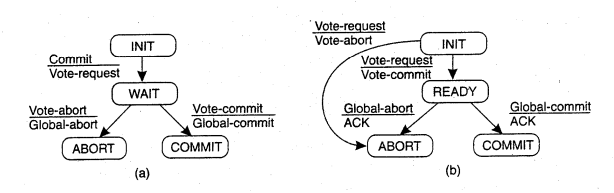
The greatest disadvantage of the two-phase commit protocol is that it is a blocking protocol. If the coordinator fails permanently, some participants will never resolve their transactions. After a participant has sent an agreement message to the coordinator, it will block until a commit or rollback is received.
A 2PC cannot dependably recover from a failure of both the coordinator and a cohort member during the commit phase. If only the coordinator had failed, and no cohort members had received a commit message, it could safely be inferred that no commit had happened. If however, both the coordinator and a cohort member failed, it is possible that the failed cohort member was the first to be notified, and had actually done the commit. Even if a new coordinator is selected, it cannot confidently proceed with the operation until it has received an agreement from all cohort members, and hence must block until all cohort members respond.
The three-phase commit protocol eliminates this problem by introducing the Prepared to commit state. If the coordinator fails before sending prepareCommit messages, the cohort will unanimously agree that the operation was aborted. The coordinator will not send out a doCommit message until all cohort members have ACKed that they are prepared to commit. This eliminates the possibility that any cohort member actually completed the transaction before all cohort members were aware of the decision to do so.
The pre-commit phase introduced above helps the system to recover when a participant or both the coordinator and a participant failed during the commit phase. When the recovery coordinator takes over after the coordinator failed during a commit phase of 2PC, the prepareCommit comes handy as follows:
- On querying participants, if it learns that some nodes are in commit phase then it assumes that the previous coordinator before crashing has made the decision to commit. Hence it can shepherd the protocol to commit.
- Similarly, if a participant says that it had not received a PrepareToCommit message, then the new coordinator can assume that the previous coordinator failed even before it completed the PrepareToCommit. Hence can safely assume that no participant has committed the changes, and hence safely abort the transaction.
FSM for coordinator and participant in 3PC:
Concurrency Control in Distributed Systems
Locking
In a distributed transaction, the locks on an objects are held locally in the same server. The local lock manager can decide whether to grant a lock or make the requesting transaction wait. However, it cannot release any locks until it knows that the transaction has been committed or aborted at all the servers involved in the transaction.
When locking is used for concurrency control, the objects remain locked and are unavailable for other transactions during the atomic commit protocol, although an aborted transaction releases its locks after phase 1 of the protocol.
Timestamp ordering
In a single server transaction, the coordinator issues a unique timestamp to each transaction when it starts. Serial equivalence is enforced by committing the versions of objects in the order of the timestamps of transactions that accessed them.
In distributed transactions, we require that each coordinator issue globally unique timestamps. A globally unique transaction timestamp is issued to the client by the first coordinator accessed by a transaction. The transaction timestamp is passed to the coordinator at each server whose objects perform an operation in the transaction.
Optimistic control
A distributed transaction is validated by a collection of independent servers, each of which validates transactions that access its own objects. This validation takes place during the first phase of the two-phase commit protocol.
Distributed Deadlocks
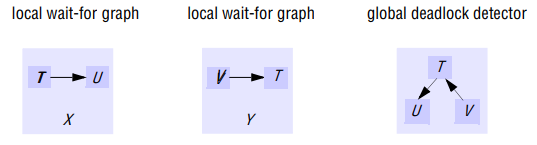
In a distributed system involving multiple servers being accessed by multiple transactions, a global wait-for-graph can in theory be constructed from the local ones. There can be a cycle in the global wait-for-graph that is not in any single local one - that is, there can be distributed deadlock.
Detection of a distributed deadlock requires a cycle to be found in the global transaction wait-for graph that is distributed among the servers that were involved in the transactions. As the global wait-for graph is held in part by each of the several servers involved, communication between these servers is required to find cycles in the graph.
A simple solution is to use centralized deadlock detection, in which one server takes on the role of global deadlock detector. From time to time, each server sends the latest copy of its local wait-for graph to the global deadlock detector, which amalgamates the information in the local graphs in order to construct a global wait-for graph. The global deadlock detector checks for cycles in the global wait-for graph. When it finds a cycle, it makes a decision on how to resolve the deadlock and tells the servers which transaction to abort.
Centralized deadlock detection is not a good idea, because it depends on a single server to carry it out. It suffers from the usual problems associated with centralized solutions in distributed systems – poor availability, lack of fault tolerance and no ability to scale. In addition, the cost of the frequent transmission of local wait-for graphs is high. If the global graph is collected less frequently, deadlocks may take longer to be detected.
Phantom deadlocks
A deadlock that is detected but is not really a deadlock is called a phantom deadlock. In distributed deadlock detection, information about wait-for relationships between transactions is transmitted from one server to another. If there is a deadlock, the necessary information will eventually be collected in one place and a cycle will be detected. As this procedure will take some time, there is a chance that one of the transactions that holds a lock will meanwhile have released it, in which case the deadlock will no longer exist.
Consider the case of a global deadlock detector that receives local wait-for graphs from servers X and Y. Suppose that transaction U then releases an object at server X and requests the one held by V at server Y. Suppose also that the global detector receives server Y’s local graph before server X’s. In this case, it would detect a cycle T → U → V → T, although the edge T → U no longer exists. This is an example of a phantom deadlock.
If transactions are using two-phase locks, they cannot release objects and then obtain more objects, and phantom deadlock cycles cannot occur in the way suggested above.
Edge chasing
A distributed approach to deadlock detection uses a technique called edge chasing or path pushing.
In this approach, the global wait-for graph is not constructed, but each of the servers involved has knowledge about some of its edges. The servers attempt to find cycles by forwarding messages called probes, which follow the edges of the graph throughout the distributed system. A probe message consists of transaction wait-for relationships representing a path in the global wait-for graph
- Initialization: When a server notes that a transaction T starts waiting for another transaction U, where U is waiting to access an object at another server, it initiates detection by sending a probe containing the edge T→ U to the server of the object at which transaction U is blocked. If U is sharing a lock, probes are sent to all the holders of the lock. Sometimes further transactions may start sharing the lock later on, in which case probes can be sent to them too.
- Detection: Detection consists of receiving probes and deciding whether a deadlock has occurred and whether to forward the probes. For example, when a server of an object receives a prbe T→U indicating that T is waiting for a transaction U that holds a local object, it check to see whether U is also waiting. If it is, the transaction it waits for (say V), is added to the probe making it T→U→V, and if new transaction V is waiting for another object elsewhere, the probe is forwarded.
In this way, paths through the global wait-for graph are built one edge at a time. Before forwarding a probe, the server checks to see whether the transaction it has just added caused the probe to contain a cycle. If this is the case, it has found a cycle in the graph and a deadlock has been detected
- Resolution: When a cycle is detected, a transaction in the cycle is aborted to break the deadlock.
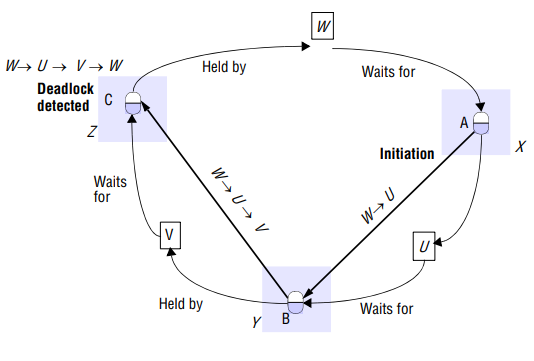 In our example,
In our example,
- Server X initiates detection by sending probe W→U to the server of B i.e. server Y.
- Server Y receives probe W→U, notes that B is held by V and appends V to the probe to produce W→U→V. It notes that V is waiting for C at server Z. This probe is forwarded to server Z.
- Server Z receives probe W→U→V, notes that C is held by W and appends W to the probe to produce W→U→V→W.
This path contains a cycle. The server detects a deadlock. One of the transactions in the cycle must be aborted to break the deadlock. The transaction to be aborted can be chosen according to transaction priorities.
Recovery
Fundamental to fault tolerance is the recovery from an error. Recall that an error is that part of a system that may lead to failure.
-
In backward recovery, the main issue is to bring the system from its present erroneous state back into a previously correct state. To do so, it will be necessary to record the system’s state from time to time, and to restore such a recorded state when things go wrong. Each time part of the system’s present state is recorded, a checkpoint is said to be made.
-
Another form of recovery is forward recovery. In this case, when the system has entered an erroneous state, instead of moving back to a previous checkpointed state, an attempt is made to bring the system in a correct new state from which it can continue to execute. The main problem with forward error recovery mechanisms is that it has to be known in advance which errors may occur. Only in that case it is it possible to correct those errors and move to a new state.
The distinction between backward and forward error recovery is easily explained when considering the implementation of reliable communication. The common approach to recover from a lost packet is to let the sender retransmit that packet. In effect, packet retransmission establishes that we attempt to go back to a previous, correct state, namely the one in which the packet that was lost is being sent. Reliable communication through packet retransmission is therefore an example of applying backward error recovery techniques.
An alternative approach is to use a method known as erasure correction. In this approach. a missing packet is constructed from other, successfully delivered packets. For example, in an block erasure code, a set of source packets is encoded into a set of longer messages encoded packets, such that a subset of encoded packets is enough to reconstruct the original source packets. If not enough packets have yet been delivered, the sender will have to continue transmitting packets until a previously lost packet can be constructed. Erasure correction is a typical example of a forward error recovery approach. The fraction k’/k, where k’ denotes the number of symbols required for recovery, is called reception frequency. Typical values are k’=16 and k=32.
- By and large, backward error recovery techniques are widely applied as a general mechanism for recovering from failures in DS. The major benefit of backward error recovery is that it is a generally applicable method independent of any specific system or process.
- First, restoring a system or process to a previous state is generally a relatively costly operation in terms of performance.
- Second, because backward error recovery mechanisms are independent of the distributed application for which they are actually used, no guarantees can be given that once recovery has taken place, the same or similar failure will not happen again.
- Finally, although backward error recovery requires checkpointing, some states can simply never be rolled back to.
Independent checkpointing
Unfortunately, the distributed nature of checkpointing (in which each process simply records its local state from time to time in an uncoordinated fashion) may make it difficult to find a recovery line. To discover a recovery line requires that each process is rolled back to its most recently saved state.
If these local states jointly do not form a distributed snapshot, further rolling back is necessary. …
Coordinated checkpointing
As its name suggests, in coordinated checkpointing all processes synchronize to jointly write their state to local stable storage. The main advantage of coordinated checkpointing is that the saved state is automatically globally consistent, so that cascaded rollbacks leading to the domino effect are avoided.
The Chandy Lamport snapshot algorithm can be used to coordinate checkpointing. This algorithm is an example of nonblocking checkpoint coordination.
A simpler solution is to use a two-phase blocking protocol. A coordinator first multicasts a checkpoint request message to all processes. When a process receives such a message, it takes a local checkpoint, queues any subsequent message handed to it by the application it is executing, and acknowledges to the coordinator that it has taken a checkpoint. When a coordinator has receives an acknowledgement from all processes, it multicasts a checkpoint done message to allow blocked processes to continue.