A collection of autonomous computing elements (hardware or software) located at networked computers communicate and coordinate their actions only by message passing and appears to its users as a single coherent system.
The advance in LAN and WAN technology made feasible to put together a computing system composed of a large numbers of networked computers generally geographically dispersed so is said to form a distributed system.
Nodes are programmed to achieve common goals which are realized by exchanging messages with each other
Examples: WWW, SUN file system, Java RPC as middleware service, CORBA?
Many web based systems are organized as relatively simple client-server architectures, core of Web site is formed by a process that has access to a local file system storing documents.
Simplest way to refer to a document is by means of reference called URL, specifies where a document is located by embedding the DNS name of its associated server along with a file name by which the server can look up the document in its local file system.
A client interacts with Web servers through a browser, which is responsible for properly displaying a document.
The communication between a browser and Web server is standardized: they both adhere to the HyperText Transfer Protocol (HTTP). Web documents have been marked up in HTMLs, in that case, the document includes various instructions expressing how its content should be displayed. One of the first enhancements to the basic architecture was support for simple user interaction by means of CGI, which defines standard way by which a Web server can execute a program taking user data as input.
Usually, user data come from an HTML form; it specifies the program that is to be executed at the server side, along with parameters values that are fitted in by the user, once the form has been completed, the program’s name and collected parameters values are sent to the server.
-
Collection of autonomous computing elements: Independent nodes means cannot assume there is something like a global clock, lack of which questions regarding synchronization and coordination. Managing group membership can be exceedingly difficult. In open group any node is allowed to join the distributed system, effectively meaning that it can send messages to any other node in the system. In contrast, with a closed group, only the members of that group can communicate with each other and separate mechanism is needed to let join or leave the group. Practice shows that a distributed system is often organized as a overlay network, a node is typically a software process equipped with a list of other processes it can directly send messages to, it may also be the case that a neighbor needs to be looked up, message passing is then done through TCP/IP or UDP channels but higher level facilities may be available as well, in any case, should be always connected, means there is always a communication path allowing those nodes to route messages from one to another.
-
Single coherent system: In a single coherent system the collection of nodes as a whole operates the same, no matter where, when, and how interaction between a user and the system takes places. On which computer a process is currently executing, or where data is stored should be of no concern, and neither should it matter, so called distribution transparency.
-
Middleware: To assist the development of distributed applications, distributed systems are often organized to have a separate layer of software that is logically placed on top of the respective OS of the computers that are part of the system. In sense, middleware is the same to a DS as what an OS is to a computer: manager of resources offering its applications to efficiently share and deploy those resources across a network, also viewed as a container of commonly used components and functions that no longer have to be implemented by applications separately.
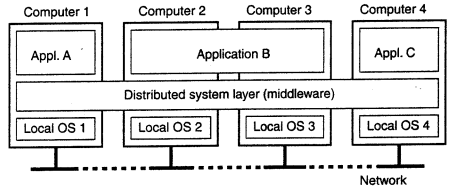
Middleware
Zoom into the actual organization of middleware, that is, independent of the overall organization of a distributed system. Middleware is an application that logically lives mostly in the OSI application layer but which contains may general purpose protocols that warrant their own layers, independent of other, more specific applications.
The DNS is a distributed service that is used to look up a network address associated with a name, in terms of OSI, DNS is an application layer, but it should be quite obvious that DNS is offering a general-purpose, application-independent service, arugably forms part of the middleware.
Authentication protocols are not closely tied to any specific application, but instead, can be integrated into a middleware system as a general service.
Two important design patterns, wrappers and interceptor:
-
Wrappers: When building a distributed system out of existing components, immediately bump into a problem: the interfaces offered by the legacy component are most likely not suitable for all applications, a wrapper is a special component that offers an interface acceptable to a client application, of which the functions are transformed into those available at the component.
-
Interceptors: Nothing but a software construct that will break the usual flow of control and allow other application specific code to be executed, are primary means for adapting middleware to the specific needs of an application.
The task of middleware is to provide a higher-level programming abstractions for the development of distributed systems and, through layering, to abstract over heterogeneity in the underlying infrastructure to promote interoperability and portability.
- Communication Abstraction
- Location Transparency
- Transaction Management
- Load Balancing
- Fault Tolerance
- Data Serialization and Deserialization
- Distributed Object Models
- Caching
Design goals
Just because it is possible to build distributed system does not necessarily mean that it is a good idea. It must meet following goals to be worth the effort.
-
Supporting resource sharing
- The main goal of a distributed system is to make it easy for the users and applications to access remote resources, and to share them in a controlled and efficient way.
- Resources can be virtually anything but typical examples include peripherals, storage facilities, data, files, services, and networks.
- A far greater significance is the sharing of higher level resources that play a part in applications, for example, user are concerned with sharing data in the form of a shared database or a set of web pages - not the disks and processors on which they are implemented.
- One obvious reason to share resources is that of economics. For example, it is cheaper to let a printer be shared by several users in a small office than having to buy and maintain separate printer for each user.
- Eg: File sharing of P2P like BitTorrent, often associated with distribution of media files such as audio and video
- For effective sharing, each resource must be managed by a program that offers a communication interface enabling the resource to be accessed and updated reliably and consistently.
-
Making distribution transparent
- Hide the fact that its processes and resources are physically distributed across multiple computers separated by large distances
- A distributed system that is able to present itself to users and applications as if it were only a single computer is said to be transparent.
| Transparency | Description |
|---|---|
| Access | Hide how an object is accessed |
| Location | Hide where an object is located |
| Migration | Hide that an object may move to another location |
| Relocation | Hide that an object may be moved to another location while in use |
| Replication | Hide that an object is replicated |
| Concurrency | Hide that an object may be shared by several independent users |
| Failure | Hide the failure and recovery of an object |
How much transparency? - Although distributed transparency is generally considered preferable for any distributed system, there are situations in which attempting to completely hide distribution aspects from users is not a good idea. - An example is requesting your electronic newspaper to appear in your mailbox before 7 A.M. local time, as usual, while you are currently at the other end of the world living in a different time. Your morning paper will not be the morning paper you are used to. - Likewise, a wide-area distributed system that connects a process in San Franscisco to process in Amsterdam cannot be expected to hide the fact that Mother Nature will not allow it to send a message from one process to the other in less than 35 milliseconds. - There is also a trade-off between a high degree of transparency and the performance of a system. For example, many Internet applications repeatedly try to contact a server before finally giving up. Consequently, attempting to mask a transient server failure before trying another one may slow down the system as a whole. In such a case, it may have been better to give up earlier, or at least let the user cancel the attempts to make contact.
-
Being open
- An open distributed system is essentially a system that offers components that can easily be used by, or integrated into other systems, at the same time itself will often consist of components that originate from elsewhere.
- To be open means the components should adhere to standard rules that describe syntax and semantics of what those components have to offer, general approach is to define services through interfaces using IDL.
- If properly specified, an interface definition allows an arbitrary process that needs a certain interface to talk to another process that provides the interface.
- Interoperability characterizes the extent by which two implementations of systems or components from different manufacturers can co-exist and work together by merely relying on each other’s services as specified by a common standard.
- Composability: Another important goal for an open distributed system is that it should be easy to configure the system out of different components (possibly from different developers).
- Extensible: Also, it should be easy to add new components or replace existing ones without affecting those components that stay in place, in other words, an open distributed system should also be extensible.
-
Being scalable
- Size scalability: Can easily add more users and resources to the system without any noticeable loss of performance.
- Geographical scalability: One in which the users and resources may lie far apart, but the fact that communication delays may be significant is hardly noticed.
- Administrative scalability: Can be easily managed even if spans many independent administrative organizations.
- In most cases, scalability problems in distributed system appear as performance problems caused by limited capacity of servers and network.
- Simply improving their capacity is often a solution known as scaling up, when it comes to scaling out, i.e. expanding the distributed system by essentially deploying more machines, three techniques:
- Hiding communication latencies: Try to avoid waiting for responses to remote service requests as much as possible, an alternative to waiting for reply to to do other useful work, can move part of computation that done at server to client.
- Partitioning and distribution: Web appears to be enormous document system but is physically paritioned across a few hundred millions servers, each handling a number of web dcouments
- Replication: Increases availability, caching is also a special form of replication making resource available in the proximity of the client acessing the resources.
Challenges
-
Heterogeneity: Is variety and differences, applies to all of networks; computer hardware; operating systems; programming languages; implementation by different developers. Although the Internet consists of many different sorts of network, their differences are masked by the fact that all of computers attached to the use the Internet protocols to communicate with one another.
-
Transparency:
-
Scalability:
-
Openness:
-
Security: Many of the information resources that are made available and maintained in distributed systems have a high intrinsic value to their users. Their security is therefore of considerable importance. Security for information resources has three components:
- confidentiality (protection against disclosure to unauthorized individuals),
- integrity (protection against alteration or corruption),
- availability (protection against inference with the means to access the resources).
-
Failure Handling When faults occur in hardware or software, programs may produce incorrect results or may stop before they have completed the intended computation. Failures in DS are partial that is, some components fail while others continue to function.
Instances
Computing systems
A important class of distributed systems is the one used for high performance computing tasks. One can make a distinction between two subgroups.
- In cluster computing, the underlying hardware consists of a collection of similar workstations or PCs, closely related by means of a high speed local area network. In each node runs the same operating system. At a certain point, it became financially and technically attractive to build a supercomputer using off the shelf tech by simply hooking up a collection of relatively simple computers in high speed network. In virtually all cases, cluster computing is used for parallel programming in which a single (compute intensive) program is run in parallel on multiple machines. One well-known example of a cluster computer is formed by Linux-based Beowulf clusters, of whose general configuration is give below. The master typically handles the allocation of nodes to a particular parallel program, maintains a batch queue of submitted jobs and provides an interface for the users of the system.
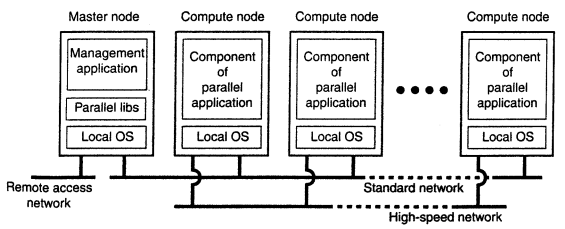
-
In contrast, grid computing systems have a high degree of heterogeneity: no assumptions are made concerning hardware, operating systems, etc. A key issue in a grid computing system is that resources from different organizations are brought together to allow the collaboration of a group of people or institutions. Such collaboration is realized in the form of virtual organization.
-
Cloud: From the perspective of grid computing, a next logical step is to simply outsource the entire infrastructure that is needed for compute-intensive applications, this is what cloud computing is all about: providing the facilities to dynamically construct an infrastructure and compose what is needed from available services. Characterized by an easily usable and accessible pool of virtualized resources.
Information systems
Another important class of distributed systems is found in organizations that were confronted with a wealth of networked applications, but for which interoperability turned out to be a painful experience. Many of the existing middleware solutions are the result of working with an infrastructure in which it was easier to integrate applications into an enterprise-wide information system.
We can distinguish several levels at which integration took place. In many cases, a networked application simply consisted of a server running that application (often including a database) and making it available to remote programs, called clients. Such clients could send a request to the server for executing a specific operation, after which a response would be sent back. Integration at the lowest level would allow clients to wrap a number of requests, possibly for different servers, into a single larger request and have it executed as a distributed transaction. The key idea was that all, or none of the requests would be executed.
Models
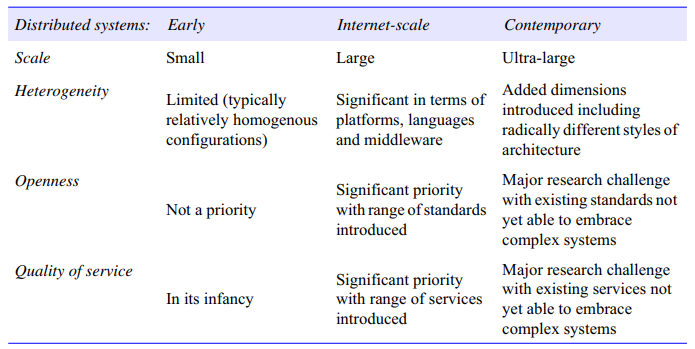
Systems that are intended for use in real-world environments should be designed to function correctly in the wildest possible rane of circumstances and in the face of many possible difficulties and threats. The properties and design issues of distributed systems can be captured and discussed through the use of descriptive models.
Physical models are the most explicit way in which to describe a system; they capture the hardware composition of a system in terms of the computers (and other devices, such as mobile phones) and their interconnecting networks.
Architectural models describe a system in terms of the computational and communication tasks performed by its computational elements; the computational elements being individual computers or aggregates of them supported by appropriate network interconnections.
Fundamental models take an abstract perspective in order to examine individual aspects of a distributed system.
Physical models
Architectural models
What is communicating and how those entities communicate together define a rich design space for the distributed systems developer to consider.
-
From a system perspective, the answer is normally very clear in that the entities that communicate in a distributed system are typically processes, leading to the prevailing view of a distributed system as processes coupled with appropriate inter-process communication paradigms. From a programming perspective, however, this is not enough, and more problem-oriented abstractions have been proposed:
-
Objects: Objects have been introduced to enable and encourage the use of object-oriented approaches in distributed systems (including both object-oriented design and object-oriented programming langauges). In distributed object-based approaches, a computation consists of a number of interacting objects representing natural units of decomposition for the given problem domain.
-
Components: Since their introduction a number of significant problems have been identified with distributed objects, and the use of component technology has emerged as a direct response to such weaknesses. Components resemble objects in that they offer problem-oriented abstractions for building distributed systems and are also accessed through interfaces. The key difference is that components specify not only their (provided) interfaces but also the assumptions they make in terms of other components/interfaces that must be present for a component to fulfil its function – in other words, making all dependencies explicit and providing a more complete contract for system construction.
We now turn our attention to how entities communicate in a distributed system and consider three types of communication paradigm:
-
Inter-process communication: refers to the relatively low-level support for communication between processes in distributed systems, including message-passing primitives, direct access to the API offered by Internet protocols (socket programming) and support for multicast communication.
-
Remote invocation: represents the most common communication paradigm in distributed systems, covering a range of techniques based on a two-way exchange between communicating entities in a distributed system and resulting in the calling of a remote operation, procedure or method. (Remote Procedure Call)
-
Group communication: is concerned with the delivery of messages to a set of recipients and hence a multiparty communication paradigm supporting one-to-many communication. Group communication relies on the abstraction of a group which is represented on the system by a group identifier. (Group Communication)
In a distributed system processes – or indeed objects, components or services, including web services (but for the sake of simplicity we use the term process throughout this section) – interact with each other to perform a useful activity, for example, to support a chat session. In doing so, the processes take on given roles, and these roles are fundamental in establishing the overall architecture to be adopted.
- Client-server: Client processes interact with individual server processes in potentially separate host computers in order to access the shared resources they manage. A server is a process implementing a specific service, for example, a file system service or a database, a client is a process that requests a service from a server by sending it request and subsequently waiting for the server’s reply. Servers may in turn be clients of other servers. For example, a web server is often a client of a local file server that manages the files in which the web pages are stored. Web servers and most other Internet services are clients of the DNS service, which translates Internet domain names to network addresses.
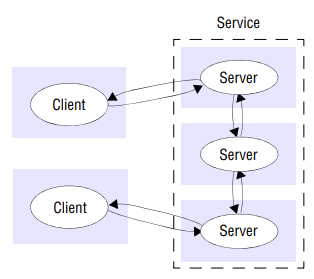
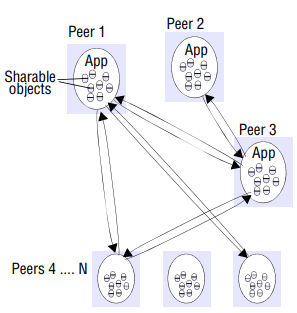
- Peer-to-peer: In this architecture all of the processes involved in a task or activity play similar roles, interacting cooperatively as peers without any distinction between client and server processes or the computers on which they run. In practical terms, all participating processes run the same program and offer the same set of interfaces to each other. While the client-server model offers a direct and relatively simple approach to the sharing of data and other resources, it scales poorly. The centralization of service provision and management implied by placing a service at a single address does not scale well beyond the capacity of the computer that hosts the service and the bandwidth of its network connections.
Failure models
In a distributed system both processes and communication channels may fail – that is, they may depart from what is considered to be correct or desirable behavior. A system that fails is not adequately providing the services it was designed for. If we consider a distributed system as a collection of servers that communicate with one another and with their clients, not adequately providing services means that servers, communication channels, or possibly both, are not doing what they are supposed to do. The failure model defines the ways in which failure may occur in order to provide an understanding of the effects of failures.
To get a better grasp on how serious a failure actually is, several classification schemes have been developed.

- A crash failure occurs when a server prematurely halts, but was working correctly until it stopped. An important aspect of crash failures is that once the server has halted, nothing is heard from it anymore. A typical example of a crash failure is an operating system that comes to a grinding halt, and for which there is only one solution: reboot it. A process crash is called fail-stop if other processes can detect certainly that the process has crashed. Fail-stop behavior can be produced in a synchronous system if the processes use timeouts to detect when other processes fail to respond and messages are guaranteed to be delivered.
- An omission failure occurs when a server fails to respond to a request. Several things might go wrong.
- The most serious are arbitrary failures, also known as Byzantine failures. In effect, when arbitrary failures occur, clients should be prepared for the worst. For example, a process may set wrong values in its data items, or it may return a wrong value in response to an invocation.

- Another class of failures is related to timing. Timing failures occur when the response lies outside a specified real-time interval.
Distributed OS
A network operating system is a specialized operating system for a network device such as an application gateway, router, or a switch. Historically operating systems with networking capabilities were described as network operating systems, because they allowed personal computers to participate in computer networks and shared file and printer access within a local area network.
Notable OS include ONOS, an open source SDN operating systems hosted by Linux foundation for communications service providers that is designed for scalability, high performance and high availability.
A distributed operating system is system software over a collection physically separate computational nodes. They handle jobs which are serviced by multiple CPUs. Each individual node holds a specific software subset of the global aggregate operating system. Each subset is a composite of two distinct service provisioners.
- The first is a ubiquitous minimal kernel, or microkernel that directly controls the node’s hardware.
- Second is higher-level collection of system management components that coordinate the node’s individual and collaborative activities.
The microkernel and the management components collection work together. They support the system’s goal of integrating multiple resources and processing functionality into an efficient and stable system. This seamless integration of individual nodes into a global system is referred to as transparency, or single system image; describing the illusion provided to users of the global system’s appearence as a single computational entity.
- The kernel: At each locale (typically a node), the kernel provides a minimally complete set of node-level utilities necessary for operating a node’s underlying hardware and resources.
- System management: System management components are software processes that define the node’s policies. These components are the part of the OS outside the kernel. These components provide higher-level communication, process and resource management, reliability, performance and security. The components match the functions of a single-entity system, adding the transparency required in a distributed environment.
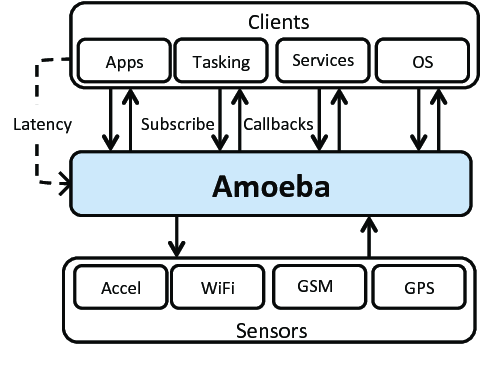
Amoeba is a distributed operating system developed by Andrew S.T. It offers multithreaded programs and a remote procedure call (RPC) mechanism for communication between threads, potentially across the network.
While Linux itself is not inherently a distributed OS, it can be configured to operate in a distributed manner using tools like the High Availability Linux Project (Linux-HA) and distributed file systems like Ceph and GlusterFS.
MACH
Mach is a kernel developed at Carnegie Mellon University to support operating system research, primarily distributed and parallel computing. Mach is often considered one of the earliest examples of a microkernel. Mach was developed as a replacement for the kernel in the BSD version of Unix.
It uses a message-passing approach for communication between different components or servers running in user space. This IPC mechanism is crucial for building distributed systems where processes need to communicate across network boundaries.
Main design goals and features:
-
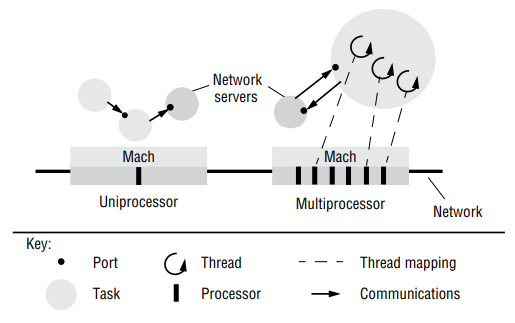
Multiprocessor operation: Mach was designed to executed on a shared memory multiprocessor so that both kernel threads and user-mode threads could be executed by any processor. Mach provides a multi-threaded model of user processes, with execution environments called tasks. Mach places a strong emphasis on efficient interprocess communication mechanisms.
-
Transparent extension to network operation: In order to allow for distributed programs that extend transparently between uniprocessors and multiprocessors across a network, Mach has adopted a local independent communication model involving ports as destinations. The Mach kernel, however, is designed to be 100% unaware of networks. The Mach design relies totally on user-level network server processes to ferry messages transparently across the network.
Abstractions;
Tasks: A Mach task is an execution environment. This consists primarily of a protected address space, and a collection of kernel-managed capabilities used for accessing ports.
Threads: Tasks can contain multiple threads. The threads belonging to a single task can execute in parallel at different processors in a shared-memory multiprocessor.
Ports: A port in Mach is a unicast, unidirectional communication channel with an associated message queue. Ports are not accessed directly by the Mach programmer and are not part of a task. Rather, the programmer is given handles to port rights. These are capabilities to send messages to a port or receive messages from a port.
The existence of ports and the use of IPC is perhaps the most fundamental difference between Mach and traditional kernels. Under UNIX, calling the kernel consists of an operation named a system call or trap. The program uses a library to place data in a well known memory location and then causes a fault, a type of error. When a system is first started, its kernel is set up to be the “handler” of all faults; thus, when a program causes a fault, the kernel takes over, examines the information passed to it, and then carries out the instructions.
Under Mach, the IPC system was used for this role instead. In order to call system functionality, a program would ask the kernel for access to a port, then use the IPC system to send messages to that port. Although sending a message requires a system call, just as a request for system functionality on other systems requires a system call, under Mach sending the message is pretty much all the kernel does; handling the actual request would be up to some other program.