A distributed file system enables programs to store and access remote files exactly as they do local ones, allowing users to access files from any computer on a network. The performance and reliability experienced for access to files stored at a server should be comparable to that for files stored on local disks.
The requirements for sharing within local networks and intranets lead to a need for different type of service - one that supports the persistent storage of data and programs of all types on behalf of clients and the consistent distribution of up-to-date data.
With the advent of distributed object-oriented programming, a need arose for the persistent storage and distribution of shared objects, one way was to serialize objects but for rapidly changing objects impractical to achieve persistence and distribution.
Distributed file system requirements:
-
Transparency: The design must balance the flexibility and scalability that derive from transparency against software complexity and performance.
-
Hardware and OS heterogeneity: The service interfaces should be defined so that client and server software can be implemented for different OS and computers.
-
Concurrent file updates: Changes to a file by one client should not interfere with the operation of other clients simultaneously accessing of changing the same file.
-
Replication:
-
Fault tolerance:
-
Consistency:
-
Efficiency: A distributed file service should offer facilities that are of at least the same power and generality as those found in conventional file systems and should achieve a comparable level of performance.
-
Security:
File service architecture
An architecture that offers a clear separation of the main concerns in providing access to files is obtained by structuring the file service as three components - a flat file service, a directory service and a client module. An abstract architectural model that underpins both NFS and AFS.
The flat file service and the directory service each export an interface for use by client programs, and their RPC interfaces, taken together, provide a comprehensive set of operations for access to files.
The client module provides a single programming interface with operations on files similar to those found in conventional file systems.
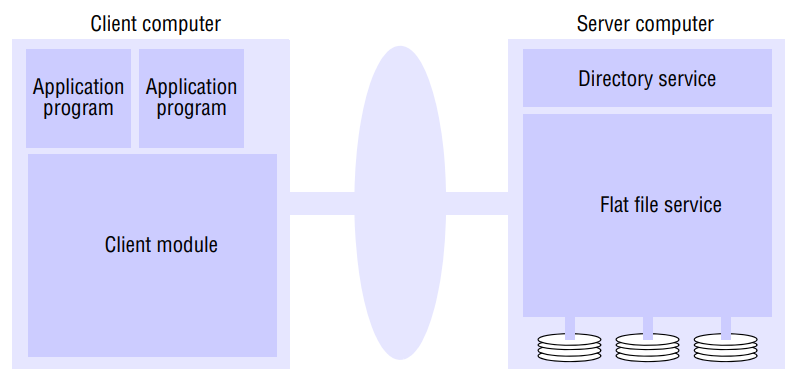
The design is open in the sense that different client modules can be used to implement different programming interfaces, simulating the file operations of a variety of different operating systems and optimizing the performance for different client and server hardware configurations.
-
Flat file service: The flat file service is concerned with implementing operations on the contents of files. Unique file identifiers (UFIDs) are used to refer to files in all requests for flat file service operations. The division of responsibilities between the file service and the directory service is based upon the use of UFIDs. UFIDs are long sequences of bits chosen so that each file has a UFID that is unique among all of the files in a DS. When the flat file service receives a request to create a file, it generates a new UFID for it and returns the UFID to the requester. The interface of flat file service is the RPC interface used by client modules. It is not normally used directly by user-level programs.
Read(FileID, i, n) → Data - throws BadPosition: If : Reads a sequence of up to items from a file starting at time and returns it in Data.
Write(FileID, i, n) → Data - throws BadPosition: If : Writes a sequence Data to a file, starting at item i, extending the file if necessary.
-
Directory service: The directory service provides a mapping between text names for files and their UFIDs. Client may obtain the UFID of a file by quoting its text name to the directory service. The directory service provides the functions needed to generate directories, to add new file names to directories and to obtain UFIDs from directories. It is a client of the flat file service; its directory files are stored in files of the flat file service. When a hierarchic file-naming scheme is adopted, as in UNIX, directories hold references to other directories.
Lookup(Dir, Name) → FileId - throws NotFound: Locates the text name in the directory and returns the relevant UFID. If Name is not in the directory, throws an execption.
-
Client module: A client module runs in each client computer, integrating and extending the operations of the flat file service and the directory service under a single application programming interface that is available to user-level programs in client computers. For example, in UNIX hosts, a client module would be provided that emulates the full set of UNIX file operations, interpreting UNIX multi-part file names by iterative requests to the directory service. The client module also holds information about the network locations of the flat file server and directory server processes. Finally, the client module can play an important role in achieving satisfactory performance through the implementation of a cache of recently used file blocks at the client.
Features:
-
Access control: In distributed implementations, access rights checks have to be performed at the server because the server RPC interface is an otherwise unprotected point of access to files. A user identity has to be passed with requests, and the server is vulnerable to forged identities. Furthermore, if the results of an access rights check were retained at the server and used for future accesses, the server would no longer be stateless.
-
Hierarchic file system: In a hierarchic directory service, the file attributes associated with files should include a type field that distinguishes between ordinary files and directories. This is used when following a path to ensure that each part of the name, except the last, refers to a directory.
-
File groups: A file group is a collection of files located on a given server. A server may hold several file groups, and groups can be moved between servers, but a file cannot change the group to which it belongs.
Sun Network File System
Sun Microsystem’s Network File System has been widely adopted in industry since its introduction in 1985. All implementations of NFS support the NFS protocol - a set of remote procedure calls that provide the means for clients to perform operations on a remote file store. The NFS protocol is operating system independent but was originally developed for the use in networks in UNIX systems.
NFS was the first file service that was designed as a product, the definitions of the key interfaces were placed in the public domain, enabling other vendors to produce implementations, and the source code for a reference implementation was made available to other computer vendors under license.
It is now supported by many vendors and the NFS protocol is an Internet standard, defined in RFCs.
NFS provides transparent access to remote files for client programs running on UNIX and other systems. The client-server relationship is symmetrical: each computer in an NFS network can act as both a client and a server, and the files at every machine can be made available for remote access by other machines.
Any computer can be a server, exporting some of its files, and a client, accessing files on other machines, but is common practice to configure larger installations with some machines as dedicated servers and others as workstations.
Important goal of NFS is to achieve a high level of support for hardware and OS heterogeneity.
The NFS server module resides in the kernel on each computer that acts as an NFS server. Request referring to files in a remote file system are translated by the client module to NFS protocol operations and then passed to NFS server module at the computer holding the relevant file system. The NFS client and server modules communicate using remote procedure calls.
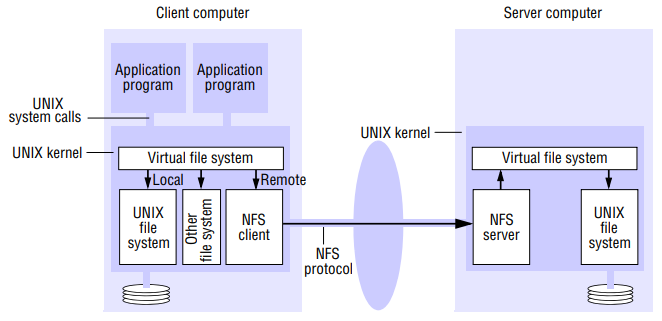
Virtual file system:
- NFS provides access transparency: user programs can issue file operations for local or remote files without distinction. Other distributed file systems may be present that support UNIX system calls, and if so, they could be integrated in same way.
- The integration of local and remote file systems without distinction is achieved by virtual file system (VFS) module, which has been added to UNIX kernel to distinguish between local and remote files and to translate between the UNIX-independent file identifiers used by NFS and the internal file identifiers normally used in UNIX and other file systems.
- In addition, VFS keeps track of file systems that are currently available both locally and remotely, and it passes each request to the appropriate local system module (the UNIX file system, the NFS client module or the service module for another file system.)
- The virtual file system layer has one VFS structure for each mounted file system and one v-node per open file. A VFS structure relates to remote file system to the local directory on which it is mounted. The v-node contains an indicator to show whether a file is local or remote.
- The file identifiers in NFS are called file handles. A file handle is opaque to clients and contains whatever information the server needs to distinguish an individual file. In UNIX implementation of NFS, the file handle is derived from the file’s i-node number by adding two extra fields: | FS identifier | i-node number of a file | i-node generation number |
- The system identifier field is a unique number that is allocated to each file-system when it is created. The i-node generation number is needed because the conventional UNIX file system i-node numbers are reused after a file is removed.
Client integration:
- The NFS client module plays the role described for the client module in flat service model, supplying an interface suitable for use by conventional applications programs. But unlike our client module, it emulates the semantics of the standard UNIX file system primitives precisely and is integrated with UNIX kernel. It is integrated with the kernel and not supplied as a library for loading into client processes so that user programs can access files via UNIX system calls without recompilation or reloading.
- It operates in a similar manner to the conventional UNIX file system, transferring blocks of files to and from the server and caching the blocks in the local memory whenever possible.
Server operations:
- The file and directory operations are integrated in a single service; the creation and insertion of file names in directories is performed in a single create operation, which takes the text name of the new file and the file handle for the target directory as arguments.
read(fh, offset, count) → attr, data: Returns up to count bytes of data from a file starting at offset. Also returns the latest attributes of the file.
write(fh, offset, count) → attr: Writes count bytes of data to a file starting a offset. Returns attributes of the file after the write has taken place.
lookup(dirfh, name) → fh, attr: Returns the file handle for the file name in the directory dirfh.
Access control and authentication:
- The NFS server is stateless and does not keep files open on behalf of its clients, so the server must check the user’s identify against the file’s access permission attributes afresh on each request.
Mounting:
- Clients use a modified version of the UNIX mount command to request mounting of a remote filesystem, specifying the remote host’s name, the pathname of a directory in the remote file system and the local name with which it is to be mounted.
Caching:
- Caching in both the client and the server computer are indispensable features of NFS implementation in order to achieve adequate performance.
- If a process issues a read or write request for a page that is already in server cache, can be satisfied without another disk access.
- When the server performs write operations, extra measures are needed to ensure that clients can be confident that the results of the write operations are persistent, even when server crashes occur.
- The NFS client caches the results to reduce the number of requests transmitted to servers.
Security:
- The security of NFS implementations has been strengthened by the use of the Kerberos scheme to authenticate clients.
Andrew FS
Distributed computing envrionment develped at CMU for use as a campus computing and information system. The design of AFS reflects an intention to support information sharing on a large scale by minimizing client-server communication
AFS was initially implemented on a network of workstations and servers running BSD UNIX and the Mach OS at CMU and was subsequently made available in commercial and public-domain versions.
Just like NFS, AFS provides transparent access to remote shared files for UNIX programs running on workstations. AFS is compatible with NFS.
AFS differs markedly from NFS in its design and implementation. The differences are primarily attributable to the identification of scalability as the most important design goal. AFS is designed to perform well with larger numbers of active users than other distributed file systems.
The key strategy for achieving scalability is the caching of whole files in client nodes.
AFS has two unusual design characteristics:
-
Whole-file serving: The entire contents of directories and files are transmitted to client computers by AFS servers. In AFS-3, files larger than 64 kbytes are transferred in 64-kbyte chunks
-
Whole-file caching: Once a copy of a file or a chunk has been transferred to a client computer it is stored in a cache used on the local disk. The cache contains several hundred of the files most recently used on that computer. The cache is permanent surviving the reboots of the client computer. Local copies are used to satisfy clients’ open requests in preference to remote copies whenever possible.
Scenario;
- When a user process in a client computer issues an open system call for a file in the shared file space and there is not a current copy of the file in the local cache, the server holding the file is located and is sent a request for a copy of the file.
- The copy is stored in the local UNIX file system in the client computer. The copy is then opened and the resulting UNIX file descriptor is returned to the client.
- Subsequent, read, write and other operations on the file by processes in the client computer are applied to the local copy.
- When the process in the client issues a close system call, if the local copy has been updated its contents are sent back to the server. The server updates the file contents and the timestamps on the file. The copy on the client’s local disk is retained in case it is needed again by a user-level process on the same workstation.
General observations and predictions based on design characteristics:
- For shared files that are infrequently updates and for files that are normally accessed by only a single user, locally cached copies are likely to remain valid for long periods.
- The local cache can be allocated a substantial proportion of the disk space on each workstation – say, 100 megabytes. This is normally sufficient for the establishment of a working set of the files used by one user.
- The design strategy is based on some assumptions about average and maximum file size and locality of reference to files in UNIX systems.
AFS is implemented as two software components that exist as UNIX processes called Vice and Venus. Vice is the name given to the server software that runs as a user-level UNIX process in each server computer, and Venus is a user-level process that runs in each client computer and corresponds to the client module in our abstract model.
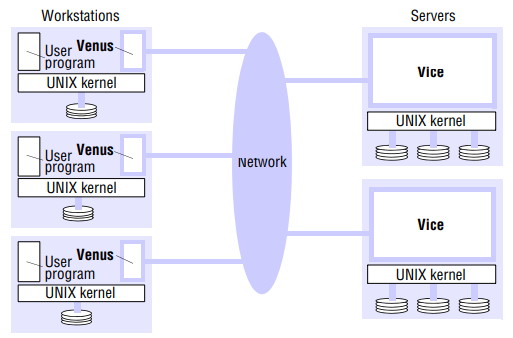
The files available to user processes running on workstations are either local or shared. Local files are handled as normal UNIX files. They are stored on workstation’s disk and are available only to local user processes. Shared files are stored on servers, and copies of them are cached on the local disks of workstations.
- A flat file service is implemented by the Vice servers, and the hierarchic directory structure by UNIX user programs is implemented by the set of Venus processes in the workstations.
- Each file and directory in the shared file space is identified by a unique, 96-bit file identifier (fid) similar to a UFID. The Venus processes translate the pathnames issued by clients to fids.