For a set of processes to coordinate their actions or to agree on one or more values.
Mutual Exclusion
Distributed processes often need to coordinate their activities, if a collection of processes share a resource or collection of resources, then often mutual exclusion is required to prevent interference and ensure consistency when accessing the resources.
Is the critical section problem, familiar in the domain of operating systems, require a solution solely based on message passing.
Consider users who update a text file, a simple means of ensuring that their updates are consistent is to allow them to access it only one at a time, by requiring the editor to lock the file before updates can be made, NFS file severs, are designed to be stateless and therefore do not support file locking, for which UNIX provide a separate file-locking service, implemented by the daemon locked, to handle locking requests from clients.
A interesting example is where there is no server, and a collection of peer processes must coordinate their accesses to shared resources among-st themselves, occurs on networks such as Ethernets and wireless in ad-hoc mode, where network interfaces cooperate as peers so that only one node transmits at a time on the shared medium.
Consider a system of processes, that do not share variables but access common resources in critical section.
Assume that the system is asynchronous, that processes do not fail and that message delivery is reliable, so that any message sent is eventually delivered intact, exactly once. (Just like in Chandy Lamport)
Essential requirements for mutual exclusion are as follows:
- Safety - At most one process may execute in the critical section (CS) at a time.
- Liveness - Requests to enter and exit the critical section eventually succeed.
Condition liveliness implies freedom from both deadlock and starvation, a deadlock would involve two or more of the processes becoming stuck indefinitely while attempting to enter or exit the critical section, by virtue of their mutual interdependence.
But even without a deadlock, a poor algorithm might lead to starvation: the indefinite postponement of entry for a process that has requested it, absence of starvation is a fairness condition.
Another fairness issue is the order in which process enter the critical section, it is not possible to order entry to the critical section by the times that the processes requested it, because of the absence of global clocks, but a useful fairness requirement that is sometimes made makes use of the happened-before order in between messages that request entry to CS.
- (→ordering) If one request to enter the CS happened-before another, than entry to the CS is granted in that order.
Evaluate the performance of algorithms for mutual exclusion according to the following criteria
- the bandwidth consumed, which is proportional to the number of messages sent in each entry and exit operation.
- the client delay incurred by a process at each entry and exit operation.
- the algorithm’s effect upon the throughput of the system, is the rate at which the collection of processes as a whole can access the critical section, given that some communication is necessary between successive processes.
The central server algorithm
Simplest way to achieve mutual exclusion is to employ a server that grants permission to enter the critical section.
To enter the critical section, a process sends a request message to the server and awaits a reply from it.
Conceptually, the reply constitutes a token signifying permission to enter the critical section.
If no other process has the token at the time of the request, then the server replies immediately, granting the token, if the token is currently held by another process, then the server does not reply, but queues the request.
When a process exits the critical section, it sends a message to the server, giving it back the token.
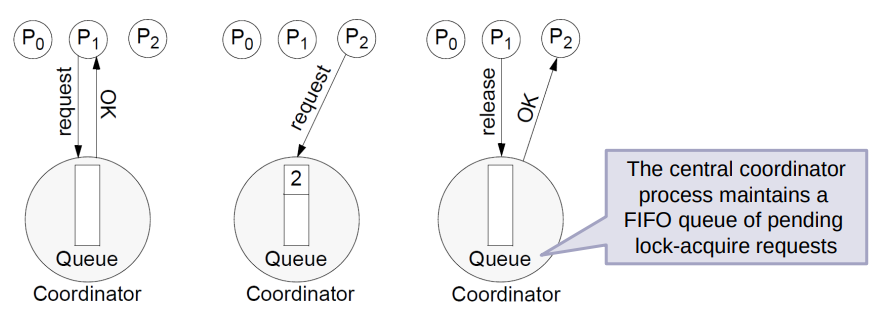
Under the assumption that no failures occur, easy to see that safety and liveliness conditions are met by this algorithm, however, does not satisfy the ordering property.
Performance evaluation:
- Entering the critical section even when no process currently occupies it takes two messages a request followed by a grant and delays the requesting process by the time required for this round-trip.
- Server may become a performance bottleneck for the system as a whole.
A ring-based algorithm
One of the simplest ways to arrange mutual exclusion between the process without requiring an additional process, is to arrange them in a logical ring, which requires that each process has a communication channel to the next process in the ring i.e.
The idea is that exclusion is conferred by obtaining a token in the form of a message passed from process in a single direction clockwise, say - around the ring.
The topology may be unrelated to the physical interconnections between the underlying computer.
Coordination and agreement in group communication
The system under consideration contains a collection of processes, which can communicate reliably over one-to-one channels. As before, processes may fail only by crashing.
The processes are members of groups, which are destinations of messages sent with the multicast operation. It is generally useful to allow processes to be members of several groups simultaneously - for example, to enable processes to receive information from several sources by joining several groups.
The operation multicast(g, m) sends the message m to all members of the group g of processes. Correspondingly, there is an operation deliver(m) that delivers a message sent by multicast to the calling process. We use the term deliver rather than receive to make clear that a multicast message is not always handed to the application layer inside the process as soon as it is received at the process’s node.
Every message m carries the unique identifier of the process sender(m) that sent it, and the unique destination group identifier group(m). We assume that processes do not lie about the origin or destinations of messages.
Basic multicast:
It is useful to have at our disposal a basic multicast primitive that guarantees, unlike IP multicast, that a correct process will eventually deliver the message, as long as the multicaster does not crash. We call the primitive B-multicast and its corresponding basic delivery primitive B-deliver. We allow processes to belong to several groups, and each message is destined for some particular group. A straightforward way to implement B-multicast is to use a reliable one-to-one send operation, as follows:
To B-multicast(): for each process , send();
On receive() at : B-deliver() at .
The implementation may use threads to perform the send operations concurrently, in an attempt to reduce the total time taken to deliver the message.
Reliable multicast:
Properties analogous to integrity and validity are clearly highly desirable in reliable multicast delivery, but we add another: a requirement that all correct processes in the group must receive a message if any of them does. It is important to realize that this is not a property of the B-multicast algorithm that is based on a reliable one-to-one send operation. The sender may fail at any point while B-multicast proceeds, so some processes may deliver a message while others do not.
On initialization
Received = {}
For process p to R-multicast mesasge m to group g
B-multicast(g,m)
On B-deliver(m) at process q with g = group(m)
if (m \not in Received)
then
Received = Received U {m};
if (q != p) then B-multicast(g, m); end if
R-deliver m;
end if
To R-multicast a message, a process Bmulticasts the message to the processes in the destination group (including itself). When the message is B-delivered, the recipient in turn B-multicasts the message to the group (if it is not the original sender), and then R-delivers the message. Since a message may arrive more than once, duplicates of the message are detected and not delivered.
Ordered multicast:
FIFO-ordered multicast (with operations FO-multicast and FO-deliver) is achieved with sequence numbers, much as we would achieve it for one-to-one communication.
The basic approach to implementing total ordering is to assign totally ordered identifiers to multicast messages so that each process makes the same ordering decision based upon these identifiers
Ricart and Agrawala
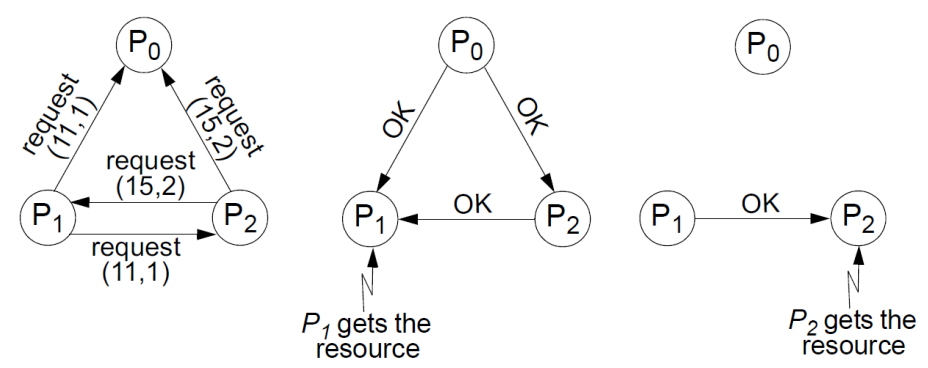
Ricart and Agrawala developed an algorithm to implement mutual exclusion between peer processes that is based upon multicast. In a distributed environment, it seems more natural to implement mutual exclusion based on distributed agreement - not on a central coordinator.
Basic idea is that processes that require entry to a critical section multicast a request message, and can enter it only when all the other processes have replied to this message.
The condition under which a process replies to a request are designed to ensure that safety, liveliness and ordering conditions are met.
The processes bear distinct numeric identifiers, are assumed to posses communication channels to each other, and each process keeps a Lamport clock.
Messages requesting entry are of the form where is the sender’s timestamp and is the sender’s identifier.
Each process records its state of being outside the critical section (RELEASED), wanting entry (WANTED) or being in the critical section (HELD) in a variable state.
On initialization: state RELEASED;
To enter the section: state WANTED; Multicast request to all processes which is of the form where is the identifier of the process. Wait until number of replies received is . state HELD;
On receipt of a request at : if (state = HELD or (state = WANTED and )) queue request from without replying else reply immediately to ; end if
To exit the critical section: state RELEASED; reply to all queued request.
If two or more processes request entry at the same time, then whichever process’s request bears the lowest timestamp will be the first to collect replies, granting it entry next.
If the requests bear equal Lamport timestamps, the requests are ordered according to the processes’ corresponding identifiers.
Performance
- If there is hardware support for multicast, , else message to multicast the request, followed by replies.
Ricard-Agrawala Second Algorithm
(wtf is this now)
A process is allowed to enter the critical section when it got the token. Initially, the token is assigned aribitrarily to one of the process.
In order to get the token, a process sends a request to all other processes competing for the same resource. The request consists of process’ logical clock and its identifier.
When a process leaves a critical section, it passes the token to open of the process waiting for it. If no process is waiting, retains the token and is allowed to enter the CS if it needs, it will pass over the token as result of an incoming request.
How does find out if there is a pending request? Doesn’t it just look into the queue? Each process records the timestamp corresponding to the last request it got from the process in request. In the token itself, token records the timestamp of ‘s last holding of the token. If request > token then has a pending request.
(wow okay, yeslai Suzuki-Kasami ni bhando raixa) The process that has the token, if it is not currently in a critical section, will then send the token to the requesting process. The algorithm makes use of increasing Request Numbers to allow messages to arrive out-of-order.
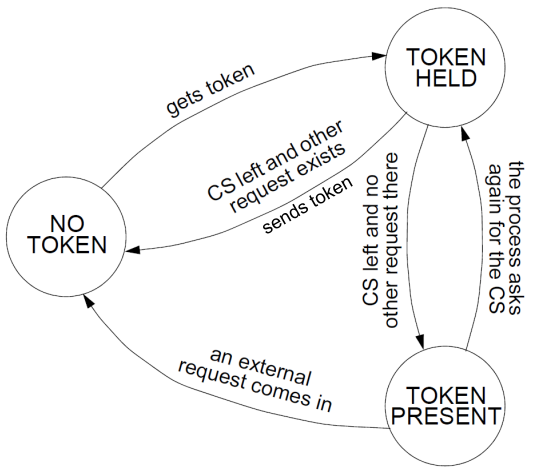
Initialization: state ← NO-TOKEN for process except for one ← TOKEN-PRESENT token initialized to 0 for all request initialized to 0 for all processes and all elements .
Rule for accessing of the CS: if state = NO-TOKEN then sends a request message to all processes; the message is of form waits until it receives the token state ← TOKEN-HELD
Rule for handling requests: request = max(request, T) if state = TOKEN-PRESENT then releases the resource (the look wala statement ma janxa) end if
Rule for releasing a CS: state ← TOKEN-PRESENT for do if request > token then state ← NO-TOKEN token ← the value of the logical clock sends the token to
Fault-tolerance so far?
Remember our assumption?
- None of the algorithms would tolerate the loss of messages if the channels were unreliable
- Central server can tolerate the crash failure of a client process that neither holds nor has requested the token.
- Ring-based cannot tolerate a crash failure of any single process.
- Ricart and Agrawala can be adapted to tolerate the crash failure of a process by taking it to grant all requests implicitly.
(OH the central server of central server algorithm failed, what to do?)
Elections
An algorithm for choosing a unique process to play a particular role is called an election algorithm.
An individual process does not call more than one election at a time, but in principle the processes could call concurrent elections.
At any point in a time, a process is either a participant - meaning that it is engaged in some run of the election algorithm - or a non-participants meaning that it is not currently engaged in any election.
Without loss of generality, require that the elected process be chosen as the one with the largest identifier, may be any useful value, as long as the identifiers are unique and totally ordered.
Each process has a variable , which will contain the identifier of the elected process, when the process first becomes a participant in an election it sets this variable to the special value to denote that it is not yet defined.
An important requirement
- Safety - A participant process has or , where is chosen as the non-crashed process at the end of the run with the largest identifier.
- Liveliness - All processes participate and eventually either set or crash.
- The choice of elected process to be unique, even if several processes call elections concurrently for same reason.
Note that there may be processes that are not yet participants, which record in the identifier of the previous elected process.
Measure the performance of an election algorithm by its total network bandwidth utilization which is proportional to the total number of messages sent, and by the turnaround time for the algorithm.
(No assumption of models here see, because each algorithm do their own assumption)
A ring-based election algorithm:
Each process has a communication channel to the next process in the ring, , and all messages are sent clockwise around the ring.
Assume that no failures occur, and that the system is asynchronous.
The goal of this algorithm is to elect a single process called the coordinator, which is the process with the largest identifier.
The initiator Initially, every process is marked as a non-participant in an election, any process can begin an election, proceeds by marking itself as a participant, placing its identifier in an election message and sending it to its clockwise neighbor.
On receiving an election message: - Compares the identifier in the message with its own: - if the arrived identifier is greater, then it forwards the message to its neighbor, - if the arrived identifier is smaller and the receiver is not a participant, then it substitutes its own identifier in the message and forwards it; - But does not forward message if it is already a participant - On forwarding an election message in any case, the process marks itself as a participant (if it lalready hasn;t.?) - If, however, the received identifier is that of the receiver itself, then this process’s identifier must be the greatest, and it becomes the coordinator. - The coordinator marks itself as a non-participant once more and sends an elected message to its neighbour, announcing its election and enclosing its identity. - When a process receives an elected message, it marks itself as a nonparticipant, sets its variable to the identifier in the message and, unless it is the new coordinator, forwards the message to its neighbor.
Useful for understanding properties of elections in general, the fact that it tolerates no failures makes it of limited practical value.
The bully algorithm
Allows processes to crash during an election, although it assumes that message delivery between processes is reliable.
Another difference is that the ring-based algorithm assumed that processes have minimal a prior knowledge of one another: each knows only how to communicate with its neighbor, and no-one knows the identifiers of the other processes, the bully algorithm, on the other hand, assumes that
- Each process knows which processes have higher identifiers, and that it can communicate with all such processes
- Unlike the ring-based algorithm, this algorithm assumes that the system is synchronous: it uses timeouts to detect a process failure.
Since the system is synchronous, can’t construct a reliable failure detector, there is a maximum message transmission delay, , and a maximum delay for processing a message
Therefore, we can calculate a time that is an upper bound on the time that can elapse between sending a message to another process and receiving a response.
Cannot just conclude that the process has crashed but know that message ain’t coming
There are three types of messages in this algorithm: - an election message is sent to announce an election; - an answer message is sent in response to an election message and - a coordinator message is sent to announce the identity of the elected process - the new coordinator
A process begins an election when it notices, through timeouts, that the coordinator has failed, several processes may discover this concurrently.
The initiator - The process that knows it has the highest identifier can elect itself as the coordinator simply by sending a coordinator message to all processes with lower identifiers. - On the other hand, a process with a lower identifier can begin an election by sending an election message to those processes that have a higher identifier and awaiting answer messages in response. - If none arrives within time , the process considers itself the coordinator and sends a coordinator message to all processes with lower identifiers announcing this. - Otherwise, if a answer message arrives, the process waits a further period for a coordinator message to arrive from the new coordinator, if none arrives, it begins another election.
On receiving an election message: - If a process receives a election message, it sends back an answer message and begins another election - unless it has begun one already.
On receiving coordinator message - If a process receives a coordinator message, it sets its variable to the identifier to the coordinator contained within it and treats that process as the coordinator.
Note when a process is started to replace a crashed process, it begins an election, if it has the highest process identifier, then it will decide that it is the coordinator and announce this to the other processes, thus it will become the coordinator, even though the current algorithm is functioning, it is for this reason that the algorithm is called the bully algorithm.
If no process is replaced, then the algorithm meets the safety condition, but not guaranteed to meet the safety condition if processes that have crashed are replaced by processes with the same identifiers, a process that replaces a crashed process may decide that it has the highest identifier just as another process which has detected crash decides that it has the highest identifier, therefore announce themselves as the coordinator concurrently.
Clearly meets the the liveliness condition, by the assumption of reliable message delivery.
Performance:
- In the best case the process with the second-highest identifier notices the coordinator’s failure, then it can immediately elect itself and send coordinator messages, the turnaround time is one message
- Requires messages in the worst case - that is, when the process with the lowest identifier first detects coordinator’s failure
Consensus and related problems
Collectively known as problems of agreement, roughly, the problem is for processes to agree on a value after one or more of the processes has proposed what that value should be
In mutual exclusion, the processes agree on which process can enter the critical region, in an election, the processes agree on which is the elected process but useful to consider more general forms of agreement in a search for common characteristics and solutions.
Definition of the consensus problem
Our system model includes a collection of processes communicating by message passing, where communication is reliable but that processes may fail.
To reach consensus, every process begins in the undecided state and proposes a single value , drawn from a set
The processes communicate with one another, exchanging values, each process then sets the value of a decision variable, , in doing so, it enters the decided state, in which it may no longer change .
The requirements of a consensus algorithm are that the following conditions should hold for every execution of it;
- Termination: Eventually each correct process sets its decision variable.
- Agreement: The decision value of all correct processes is the same: if and are correct and have entered the decided state, then =
- Integrity: If the correct processes all proposed the same value, then any correct process in the decided state has chosen that value.
What if no processes fail?
Consider a system in which processes cannot fail, then is straightforward to solve consensus, for example, can collect the processes into a group and have each process reliably multicast its proposed value to the members of the group.
Each process waits until it has collected all values (including its own), then evaluates the function , which returns the value that occurs most often among its arguments, or the special value not in if no majority exists.
Termination is guaranteed by the reliability of the multicast operation, agreement and integrity are guaranteed by the definition and majority and integrity property of a reliable multicast.
Ways processes can fail?
If processes can fail this introduces the complication of detecting failures, and it is not immediately clear that a run of the consensus algorithm can terminate, in fact, if the system is asynchronous, then it may not.
If processes can fail in arbitrary (Byzantine) ways, then faulty processes can in principle communicate random values to the others.
Byzantine problem
In the informal statement of the Byzantine generals problem, three or more generals are to agree to attack or to retreat.
One, the commander, issues the order. The others, lieutenants to the commander, must decide whether to attack or retreat.
But one or more of the generals may be ‘treacherous’ – that is, faulty, if the commander is treacherous, he proposes attacking to one general and retreating to another, if a lieutenant is treacherous, he tells one of his peers that the commander told him to attack and another that they are to retreat.
Solution
- Termination: eventually each correct process sets its decision variable.
- Agreement: decision value of all correct processes is the same.
- Integrity: if the commander is correct, then all processes decide on the value that the commander proposed.
Consensus in a synchronous system
Crash failure
Assumes that up to of the processes exhibit crash failures, correct processes can detect the absence of a message through a timeout.
At most processes may crash, by assumption, at worst, all crashes will occur during the rounds, but the algorithm guarantees that at the end of the rounds all the correct processes that have survived will be in a position to agree.
To reach consensus, each correct process collects proposed values from the other processes.
The algorithm proceeds in rounds, in each of which the correct processes multicast the values between themselves.
The variable holds the set of proposed values known to process at the beginning of round .
On initialization
In round () Multicast only values that have not been sent while (in round ) On getting value from
After rounds
Given that the algorithm assumes crash failures at worst, the proposed values of correct and non-correct processes would not be expected to differ, at least not on the basis of failures. The revised form of integrity enables the convenient use of minimum function to choose a decision value from those proposed.
Byzantine generals
Here, a faulty process may send any message with any value at any time; and it may omit to send any message.
Up to of the processes may be faulty, correct processes can detect the absence of a message through a timeout.
Lamport considered the case of three process that send unsigned messages to one another, showed that there is no solution that guarantees to meed the conditions of the Byzantine generals problem if one process is allowed to fail.
Generalized the result to show that no solution exists if , went on to give an algorithm that solves the Byzantine in a synchronous system if for unsigned messages.
Impossibility with three process
Two cases, in the left-hand one of the lieutenants, , is faulty; on the right the commander, , is faulty.
Read ’:’ symbol as ‘says’; for examples, ‘3:1:u’ is the message ‘3 says 1 says u’.
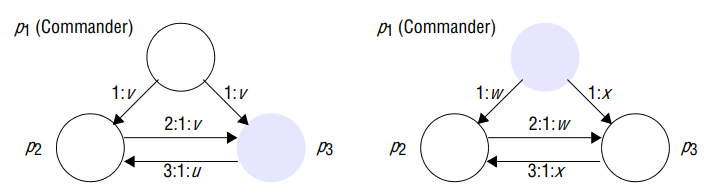
Lefthand configuration:
- The commander correctly sends the same value to each of the other two processes, and correctly echoes this to , however, sends a value to
- All knows at this stage is that it has received differing values; it cannot tell which were sent out by the commander (since it does not know whether lieutenant or commander is faulty).
Righthand configuration:
- Commander sends different values to the lieutenants, after has correctly echoed it’s value that is received, is in the same situation as it was in when was faulty; it has received two different values.
If a solution exists, then process is bound to decide on value when the commander is correct, by the integrity condition, if we accept that no algorithm can possibly distinguish between two scenario, must also choose the value sent by the commander in the right hand scenario.
Impossibility with .
Solution with one faulty process, .
The correct generals reach agreement in two rounds of messages:
- In the first round, the commander sends a value to each of the lieutenants.
- In the second round, each of the lieutenants sends the value received to its peers
A lieutenant receives a value from the commander, plus values from its peers, if the commander is faulty, then all the lieutenants are correct and each will have gathered exactly the set of values that the commander sent out.
Otherwise, one of the lieutenants is faulty; each of its correct peers receives copies of the value that the commander sent, plus a value that the faulty lieutenant sent to it.
In either case, the correct lieutenants need only apply a simple majority function to the set of values they receive.
Since , , therefore, the majority function will ignore any value that a faulty lieutenant sent, and it will produce the value that the commander sent if the commander is correct.
Performance:
In the general case, the Lamport algorithm operates over rounds, in each round, a process sends to a subset of the other processes the values that it received in the previous round: is very costly as involves sending messages.
Consensus in asynchronous system
The synchronous algorithms assume that message exchanges take place in rounds, and that processes are entitled to time out and assume that a faulty process has not sent them a message within the round, because the maximum delay has exceeded.
No algorithm can guarantee to reach consensus in an asynchronous system, even with one process crash failure, in an asynchronous system, processes can respond to messages at arbitrary times, so a crashed process is indistinguishable from a slow one.
(aile samma chai process fail ko assumption gariyeko xa ra yo assumption bhitra yedi message aayena bhane process fail bhayeko mandini ho tara nabhako huna pani sakxa)