Array:
An array is a data structure consisting of a collection of elements (values or variables), of same memory size, each identified by at least one array index or key.
An array is stored such that the position of each element can be computed from its index tuple by a mathematical formula.
1D:
A one-dimensional array is a type of linear array. Accessing its elements involves a single subscript which can either represent a row or column index. For a vector with linear addressing, the element with index is located at the address , where is a fixed base address and is a fixed constant, sometimes called the address increment or stride.
Multi:
For a multidimensional array, the element with indices would have addresses where the coefficients and are the row and column address increments, respectively.
More generally, in a dimensional array, the address of an element with indices is
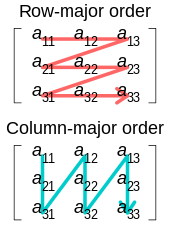
Often the coefficients are chosen so that the elements occupy a contiguous area of memory. However, that is not necessary.
Comparison with other data structures:
| Data structures | Peek | Beginning | End | Middle | Excess space, average |
|---|---|---|---|---|---|
| Array | - | - | - | ||
| Linked list | |||||
| Dynamic array | |||||
| Balanced tree | |||||
| Hashed array tree |
Dynamic arrays are similar to arrays but add the ability to insert and delete elements; adding and deleting at the end is particularly efficient. However, they reserve linear additional storage whereas arrays do not reserve additional storage.
Prefix sums
The array is referred to as an array of prefix sums, is defined such that each element represents the sum of elements from the original array to , inclusive.
It’s defined as:
is always set to .
For in the range from to , is calculated as follows:
In other words, stores the cumulative sum of the elements in the original array up to index
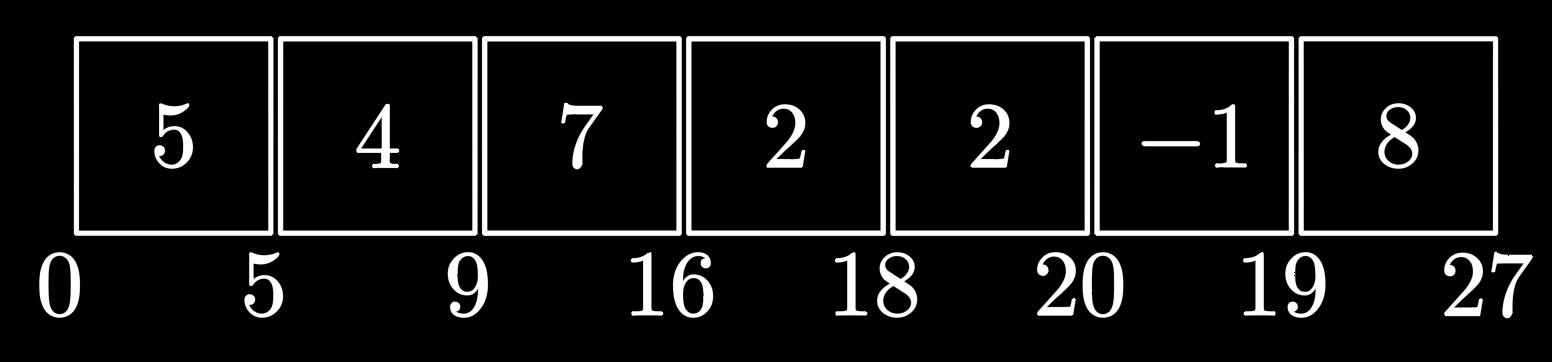
It is also worth remembering that the length of the array one more than the length of the array .
Formula for can be written recursively:
Zero-sum subsegment
Problem: Given an array of integers, find any non-empty subsegment with a sum of elements equal to zero.
Constraint: Solve this problem in time complexity.
Solution: Create a dictionary to store the prefix sums encountered so far along with their corresponding indices.
Product except oneself
Problem: Given an array of integers and an index , find the products of all elements in the original array except for the element at index .
Constraint: Find the solution in time complexity.
Solution: Calculate prefix and suffix products and combine them to obtain the result.
Hashing search
Hash map is a data structure that implements an associative array, also called a dictionary, which is an abstract data type that maps keys to values.
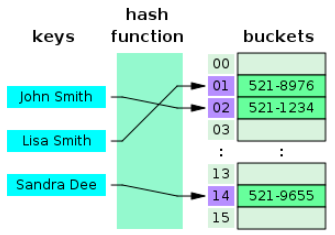
Data structures like hash maps and sets turn out to be very useful for solving a wide range of problems, especially problems that involve searching, counting, and identifying relationships between elements.
2Sum
Problem: Given an array of integers, find two numbers such that they add up to a specific target sum. Constraint: Solve this problem in time complexity.
Iterative:
Loop i: 1 to n-1
Loop j: i+1 to n
is a[i]+a[j]==0?
Hashify:
Loop i: 1 to n
map(a[i]) = i
Loop i: 1 to n-1:
target = -a[i]
is target in map? and map[target] > i?
3Sum Problem: Given an array of integers, find all triplets such that they add up to a specific target sum. Constraint: Solve this problem in time complexity.
Iterative:
sort (for unique triplets)
Loop i: 1 to n-2
Loop j: i+1 to n-1
Loop k: j+1 to n
is a[i]+a[j]+a[k]==0?
Hashify:
sort (for unique triplets)
Loop i: 1 to n
map(a[i]) = i
Loop i: 1 to n-2
Loop j: i+1 to n-1
target = -a[i]-a[j]
is target in map? and map[target] > j?
Problem: Given an array of integers and a target sum, count the number of subarrays whose elements sum to the target sum. Constraint: Solve this problem in time complexity.
prev = {}
curr = 0
count = 0
for i in nums:
curr += i
if curr == target:
count += 1
if (curr-target) in prev:
count += prev[curr-target]
prev[curr] += 1
return count
Two pointers
(pattern: minimizing, maximizing, counting, (not function on) segments with constraints)
The two-pointer method solves problems related to finding the longest or shortest good segments or counting the number of such segments when the following conditions are met:
- if a segment is good, then any segment nested withn it is also good.
- if a segment is good, then any segment that contains it is also good.
Segment with maximum good sum
Problem: Given an array consisting of non-negative numbers, find a segment , the sum of elements within which does not exceed and the length of the segment is maximum.
Constraint: Solve the problem in time complexity.
Solution:
x = 0
L = 0
for R = 0...n-1
x += a[R]
while x > s and L <= R:
x -= a[L]
L++
res = max(res, R-L+1)
count += R-L+1
In general:
Initialize variables that keep track of goodness parameter updatable as we iterate.
L = 0
for R = 0...n-1
update goodness wrt R
while not good and L <= R:
update goodness wrt L
increment L
[L,R] is good here;
Segment with minimum good sum
Problem: Given an array consisting of non-negative numbers, find a segment , the sum of elements within which exceeds and the length of the segment is minimum.
Constraint: Solve the problem in time complexity.
Solution:
x = 0
L = 0
for R = 0...n-1
x += a[R]
while x - a[L] >= s and L <= R:
x -= a[L]
L++
if x >= s:
rest = min(res, R-L+1)
count += L+1
In general:
Initialize variables that keep track of goodness parameter updatable as we iterate.
L = 0
for R = 0...n-1
update goodness wrt R
while good on excluding a[L] and L <= R:
update goodness wrt L
increment L
if good:
[L,R] is good here;
Segment with small set
Problem: Given an array consisting of non-negative numbers, find the number of segments within which there are no more than unique elements on this segment.
Constraint:
Solution:
count = 0
map u
L = 0
for R = 0...n-1
u[a[R]]++;
while (u.size() > k) and L <= R:
u[a[L]]--;
L++
count += (R-L+1)
Permutation in string
Problem: Given two strings and , return true if contains an anagram of , or false otherwise.
Looped playlist
Problem: Given a playlist with songs with their positivity scores and the amount that you want increase his mood. Find index of the song , with which you should start listening, and the number of songs , which you should listen to.
Binary search
(pattern: searching; minimizing, maximizing, functions on segments with constraints)
Given an array all numbers are divided into good and bad, if is good, then is also good. The goal is to find the minimum good number. We set two pointers and are set such that points to a bad element and to a good one. That is, and . If there are no such numbers, we will create a fictitious elements for which the invariant is fulfilled. Until the points and point to adjacent numbers, we do the following:
- Set to
- If , then is good, therefore, replace with , else replace with At the end end, and will be such that they will point to bad and good that are adjacent to each other.
Solution:
L = 0
R = N+1
while (L+1<R):
mid = (L+R)//2
if (mid is good) left = mid else right = mid
if R = N+1: no goods
Searching an item in an array
good(mid): numsmid target
Searching an item in a matrix
good(mid): matrixmid/col, mid%col target
Searching an item in a rotated array
good(mid): if on the same side numsmid target else accordingly
Root of a function
L = -ve
R = +ve
for t in range(100):
mid = (L+R)/2
if f(mid)>0; right = mid else left = mid
Minima of a function
L = [<minima]
R = [>minima]
for t in range(100):
mid = (L+R)/2
if can_f_possibly_attain_mid? right = mid else left = mid
Usually, can_f_possibly_attain_mid? = whether_task_can_be_done_with_constraint_mid?
Main deal: devise a function of constraint that says something is possible within that constraint
Problem:
Problem: There are people on a straight line, they need to gather at one point. Each person knows his current position and his speed . Help them find out in what minimum time they can gather at one point. Say we choose a point . Each person takes time to reach there. So . We have to vary such that is minimum:
can_f_possibly_attain_mid = can_each_of_i_reach_at_one_common_place_in_mid_time?
Find if there is a valid interval between the nearest left and right boundaries considering each person.
Problem: Given an array of positive integers. Your task is to divide it into segments so that the maximum sum on the segment is the minimum possible. Print one number, the minimum possible maximum sum on the segment:
can_f_possibly_attain_mid = is_no_of_segments_with_maximum_sum_mid_greater_than_k?
Iterate to find out segment counts accumulating the sum as we move and restarting once it reaches limit.
Problem: Given an array of and a number . Your task is to find a segment of length at least , on which the arithmetic mean of the elements is maximum possible:
can_f_possibly_attain_mid = is_there_a_seg_with_mean_>_mid_with_length_at_least_d?
(prefix sum trick?)
Linked lists
is a data structure consisting of a collection of nodes which together represent a sequence, in its most basic form, each node contains data, and a reference (in other words, a link) to the next node in the sequence:
Insert at beginning (Value Y):
Node* A = new Node;
A->Data = Y;
A->Link = H;
H = A;
return H
Delete at beginning ():
if H == null: underflow
Node* A = H;
H = A->Link;
Value = A->Data;
delete A;
return Value;
Insert after (Node* P, Value Y):
Node* A = new Node;
A->Data = Y;
A->Link = P->Link;
P->Link = A;
return A
Delete after (Node* P):
if P->Link == nullptr: List ends here
Node *A = P->Link;
P->Link = A->Link;
Value = A->Data;
delete A;
return Value;
Iterating a linked list
current = H
while current != nullptr:
do something with currnet.val
current = current->Link
Middle of a linked list
if H == nullptr return None
slow, fast = H, H
while fast and fast.next:
slow = slow.next
fast = fast.next.next
return slow
Reversing a linked list
if H == nullptr return H;
current = H
prev = nullptr
while current != nullptr:
next_node = current.Link #Because link of current is about to change
current.Link = prev
prev = current #Now move on
current = next_node
Merge sorted link list
H = new Node
current = H
while l1 and l2:
if l1.val < l2.val:
current.next = list1
list1 = list1.next
else:
current.next = list2
list2 = list2.next
current = current.next
if list1:
current.next = list1
else:
current.next = list2
Reordering the linked list
find middle of the list, reverse the second half, merge the two halves
Binary trees
is a tree data structure in which each node has at most two children, referred to as the left child and the right child. A recursive set theoretic definition is that a binary tree is a tuple where and are binary trees or the empty set and is a singleton set containing the root.
The BST is an ordered binary tree with the key of each internal node being greater than all the keys in the respective node’s left subtree and less than the ones in its right subtree.
Inorder traversal:
(returns result list of inorder T)
if T is None:
return []
result = []
result += inorderTraversal(root.left)
result.append(root.val)
result += inorderTraversal(root.right)
OR:
result = []
stack = []
current = T
while current is not None or stack:
stack.append(current)
current = current.left
current = stack.pop()
result.append(current.val)
current = current.right
Searching or inserting BST for a value:
(returns root of tree after inserting the value)
if root is None:
return TreeNode(val)
if val == root.val:
return root
elif val < root.val:
root.left = searchAndInsert(root.left, val)
else:
root.right = searchAndInsert(root.right, val)
return root
Invert a binary tree:
if root is None:
return None
root.left, root.right = root.right, root.left
invertTree(root.left)
invertTree(root.right)
return root
**Deleting a value from the BST:**
Delete a node in binary tree:
???
Maximum depth of a binary tree:
if root is None:
return 0
return max(self.maxDepth(root.left)+1, self.maxDepth(root.right)+1)
We enter the realm of recursiveness:
problems → subproblems; a linear or a tree exploison;
Permutations and combinations with constraints
(remember itertools?)
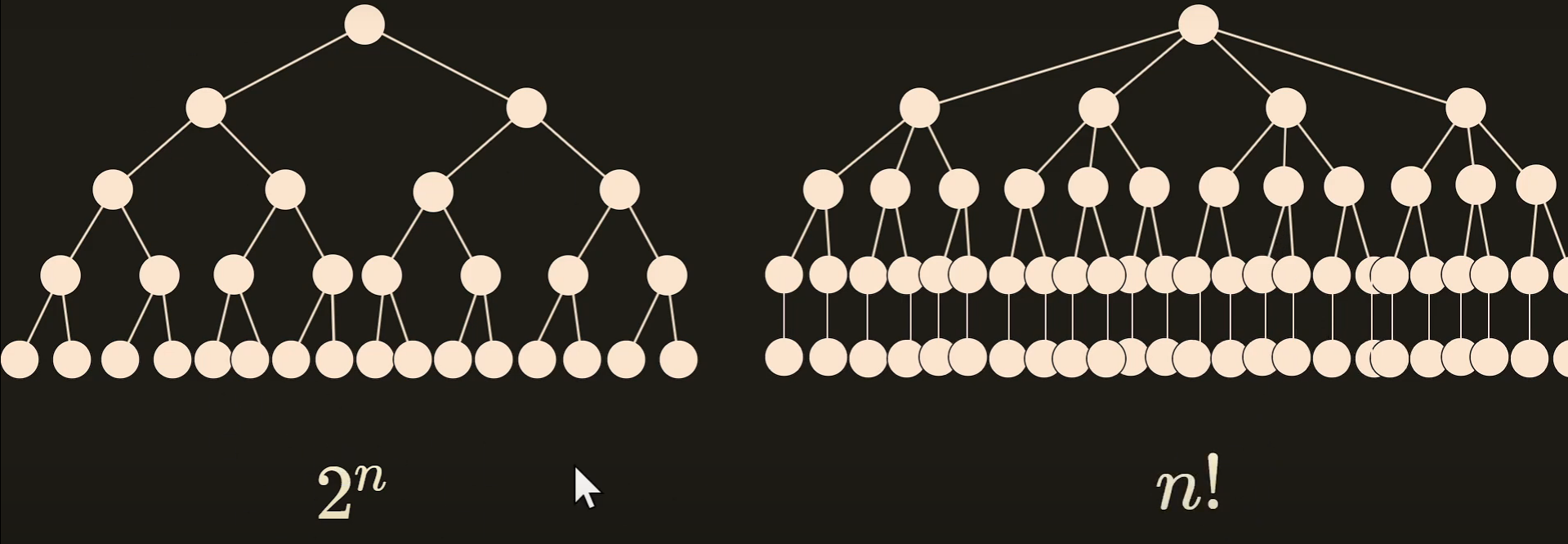
Permutations, the tree expands in which node to take in, so all possible paths from root of each node is a permutation, the permutation of size n are the leaf nodes Combinations, the tree expands in either choosing a particular node or not, so all permutation (any size) are available in leaf
For generating permutations of size we need to consider each nodes:
res = []
dfs(nums, [], res)
#using elements of nums generate permutations to running path finally add results
dfs(nums, path):
---path is your permutation---
res.append(path) # each node
if not nums:
return
---is their any bound condn---
for i in range(len(nums)):
dfs(nums[:i]+nums[i+1:], path+[nums[i]])
Generate combinations (2^n tree) → 2^n nodes
res = []
dfs(nums, [], res)
#using elements from start of nums generate combinations to running path finally add results
dfs(nums, path):
---path is your combination---
if nums is None:
res.append(path) # leaves only
return
---is their any bound condn---
dfs(nums[1:], path)
dfs(nums[1:], path+[nums[0]])
Note: This produces multiple empty combinations
Also, you could pass nums unchanged even after appending nums[0] to path but need stop codn:
Many(>3)sum:
Problem: Given an array of ints, is it possible to choose a group of some of the ints, such that the group sums to the given target?
groupSum(nums, target):
if target == 0:
return True
if not nums or target < 0:
return False
#either pick the number or dont pick it, move on in both cases:
return groupSum(nums[1:], target-nums[0]) || groupSum(nums[1:], target)
groupSum(nums, target):
if target == 0:
return True
if not nums or target < 0:
return False
#either pick the number or dont pict it, move on latter case only:
return groupSum(nums, target-nums[0]) || groupSum(nums[1:], target) #target<0 is stop?
Find groupSum:
res = []
def dfs(nums, path, target):
if not nums:
if target == 0:
res.append(path)
return
if target < 0: #for combinations with replacements
return
dfs(nums[1:], path, target)
dfs(nums, path+[nums[0]], target-nums[0])
dfs(candidates, [], target)
return res
All possible paths in a binary tree:
res = []
def dfs(root, path):
if root.left is None and root.right is None:
res.append(path+[root.val])
return
if root.left is not None:
dfs(root.left, path+[root.val])
if root.right is not None:
dfs(root.right, path+[root.val])
dfs(root, [])
Graph algorithms
A graph is a structure amounting to a set of objects in which some pairs of the objects are in some sense related. The object corresponds to mathematical abstractions called vertices and each of the related pairs of vertices is called an edge. The edges may be directed or undirected.
Adjaceny list: Vertices are stored as records or objects, and every vertex stores a list of adjacent vertices. This data structure allows the storage of additional data on the vertices. Additional data can be stored if edges are also stored as objects, in which case each vertex stores its incident edges and each edge stores its incident vertices.
Adjacency matrix: A two-dimensional matrix, in which the rows represent source vertices and columns represent destination vertices. Data on edges and vertices must be stored externally. Only the cost for one edge can be stored between each pair of vertices.
Traversal: (cycles don’t affect)
visited = [False for _ in range(vertices)]
dfslist = []
def dfs(current):
#take action on vertex affter entering the vertex (DFS order)
dfslist.append(current)
visited[current] = True
for adj in adj_list[current]:
if not visited[adj]:
#take action on child before entering the child node
dfs(adj)
#else:
#can also do something to already visited children
#take action on vertex before exiting the vertex node
Note: dfs is like generating permutations, it usually not return anything but change external structures:
Check if a path exists:
visited = [False for _ in range(vertices)]
def dfs(current):
if current == destination:
return True
visited[current] = True
for adj in adj_list[current]:
if not visited[adj]:
if dfs(adj):
return True
return False
return dfs(current)
Connectivity:
visited = [False for _ in range(vertices)]
dfslist = []
def dfs(current):
dfslist.append(current)
visited[current] = True
for adj in adj_list[current]:
if not visited[adj]:
dfs(adj)
count = 0
for node in range(vertices):
if not visited[node]:
count += 1
dfs(node)
dfslist.append("-")
print(dfslist)
Bipartite check: (quite complex) For each unvisited node we color it opposite to that of its parent, and for each visited node we check if its color is opposite to its parent, since a node can be children of multiple nodes:
visited = [False for _ in range(vertices)]
color = [-1 for _ in range(vertices)] #nocolor?
def dfs(current):
visited[current] = True
for adj in adj_list[current]:
if not visited[adj]:
color[adj] = 1-color[current]
if not dfs(adj):
return False
else:
if color[current] == color[adj]:
return False
color[0]
return dfs(0)
Topological sort: is a linear ordering of vertices such that for every directed edge (u,v) from vertex u to v, u comes before v in the ordering (u→v: u depends on v):
visited = [False for _ in range(vertices)]
topoorder = []
def dfs(current):
visited[current] = True
for adj in adj_list[current]:
if not visited[adj]:
dfs(adj)
topoorder.append(current)
for each_vertex in range(vertices):
if not visited[each_vertex]:
dfs(each_vertex)
Cycle detection (whether or not?)
visited = [False for _ in range(vertices)]
rec_stack = [False for _ in range(vertices)]
has_cycle = False
def dfs(current):
nonlocal has_cycle
visited[current] = True
rec_stack[current] = True
for adj in adj-list[current]:
if not visited[adj]:
dfs(adjacents)
elif rec_stack[adj]:
has_cycle = True
return
rec_stack[current] = False
for each_vertex in range(vertices):
if not visited[each_vertex]:
dfs(each_vertex)
print(has_cycle)
Find all cycles:
visited = [False for _ in range(vertices)]
rec_stack = [False for _ in range(vertices)]
cycles = []
def dfs(current):
visited[current] = True
rec_stack[current] = True
path.append(current)
for adj in adj_list[current]:
if not visited[adj]:
dfs(adj)
elif rec_stack[adj]:
cycle = path[path.index(adj):] + [adj]
cycles.append(cycle)
rec_stack[current] = False
path.pop()
for each_vertex in range(vertices)
if not visited[each_vertex]:
dfs(each_vertex)
print(cycles)
Dynamic programming
- S: Divide the problem into subproblem and express the original problem in terms of subproblems
- R: Relate the subproblems by a recurrence relation
- B: Provide the base cases
- T: Find the topological order in which to solve the subproblems to reach the final problem
Fibonacci:
memo = {}
fib(n):
if n in memo: return memo[n]
if n <= 2: F = 1
else: F = fib(n-1) + fib(n-2)
memo[n] = F
return F
OR:
Bottomup approach:
fib = [-1]*(n+1)
fib(n):
for k = 1 TO n
if k <= 2: F = 1
else: F = fib[k-1] + fib[k-2]
fib[k] = F
return fib[n]
Counting k steps or minimum cost: (staircase or frog jumps)
memo = {}
cost(n):
if n in memo:
return memo[n]
if n <= 0:
val = 0
else:
val = [cost(n-i)+abs(h[n]-h[n-i]) for i in range(1,k+1) if n-i >= 0]
memo[n] = val
return val
dp = [inf]*(n+1)
dp[1] = 0
#dp[i] = minimum cost to reach
for i in range(1, n+1):
for j in range(i+1, i+k+1):
if j <= n:
dp[j] = min(dp[j], dp[i]+abs(h[j]-h[i]))
return dp[n]
In bottom up dp, each child updates its parent, so we need an initialization at first. The children updates the parent what it would have returned if it was a function call:
Knapsack: Given N items and a knapsack with capacity W, find the maximum possible sum of the values of items:
Kadane: Given an array of integers, find the subarray with the maximum sum of elements.
Example: Longest common subsequence:
TRICK: For two pair of inputs, product their individual subproblems
1) L(i,j)[prefix*prefix] = To find LCS in the prefix (0,...,i) of the first string and in the prefix (0,...,j) of the second string, To find L(N-1,N-1)?
2) L(i,j) = 1+L(i-1,j-1) if A[i] = A[j]
max{L(i-1,j), L(i,j-1)} else
[i, j >= 1]
3) L(0,*) = 1 if A[0] = B[*]
L(0,j-1) else
L(*,0) = 1 if A[*] = B[0]
L(i-1,0)
4) Order is to go from outerly 1, ..., N-1 and innerly 1, ..., N-1
Example: Longest Increasing Subsequence:
1) L(i)[prefix] = To find LIS in the prefix 0,1,2,...,i of the string, To find L(N-1)?
2) L(i) = 1+L(i-1) if A(i) is in the longest subsequence of L(i-1)
L(i-1) else
TRICK: If the obvious seeming subproblem is not giving a way, put some constraints at the end of the subproblem
1') L(i)[prefix] = To find LIS in the prefix 0,1,2,...,i where A[i] is the part (so ends with it) of the sequence, To find max{L(i); where 0<=i<=N-1}?
2') L(i) = 1+max{L(j); where 0<=j<i for which A[i]>A[j]}
1 else
[i >= 1]
3) L(0) = 1
4) Order is to from 1 to N-1
Example: Alternating coin game:
TRICK: Sometimes the expansion of sub-problem by introducing third parameter might be needed beside the obvious ones
1) X(i,j,p)[substring] = To find the max coin you could get (when you opponent is dumb) in the substring i,...,j when the player p moves first, To find X(1,N,p)?
2) X(i,j,p): X(i,j,me) = max{v(i)+X(i-1,j,me), v(j)+X(i,j-1,you)}
min{X(i-1,j,you), X(i,j-1,you)}
[i < j]
3) X(*,*,me) = v(*), X(*,*,you) = 0
4) Order is from outerly j = 1 to N and innerly i = 1 to j-1
Example: MA Arithmetic Parenthesis:
TRICK: Some further expansion of sub-problem
1) X(i,j,opt)[substring/kindof] = To find opt value for i,...,j, To find X(1,N,max)
2) X(i,j,opt) = opt{X(i,k,optl)*_k(X(k,j,optr) where i<=k<j and optl,optr in {min,max}
[i < j]
3) X(*,*,opt) = a(*)
4) Order is from outer j = 1 to N and inner i = 1 to j-1
Example: Piano Fingering:
1) X(i,f) = To find min total difficulty to play t1,...,ti ending with finger f, To find min(1<=f<=F) X(N,f)
2) X(i,f) = min(1<=f'<=F){X(i-1,f')+d(t(i),f',t(i+1),f)}
[i >= 2]]
3) X(1,f) = 0
4) Order is from i = 2 to N
Patterns so far:
Map for any kind of search involved When subarray containing a good subarray is also good Binary search pattern Minimization Recursion Permutation and combination recursion