Why human language is different?
Human language is unique from the language of other animals in its compositionality. This compositionality allows the endless capability for generating a new sentence. For instance, with just 25 different words for each role — the role of subject, verb, and object — it is possible to generate over 15,000 distinct sentences.
Ambiguity:
- Phonological ambiguity:
- Lexical ambiguity:
- Syntactic ambiguity:
- Semantic ambiguity:
- Pragmatic ambiguity:
Toolkits
NTLK:
provides interface to a large number of corpus. A corpus is a large collection of text.
corpus:
Few methods in corpus reader are:
fileids(): lists the name of the text documents i.e. each book in gutenberg.raw()words()sents()(needpunct_tabcorpus)
import nltk
nltk.download('gutenberg')
nltk.gutenberg.raw(nltk.gutenberg.fileids[0])-
Gutenberg is a small selection from the Project Gutenberg electronic text archive, which contains some 25,000 free electronic books.
-
Webtext is a small collection from Firefox discussion forum, conversations overhead in New York, the movie script of Pirates of Carribean, personal advertisement, and wine reviews.
-
The Brown Corpus was the first million-word electronic corpus of English, created in 1961 at Brown University.
tokenize:
nltk.tokenize.word/sent_tokenize(text, language='english')
SpaCy:
SpaCy has around 46 statistical model in over 15 languages.
!python3 -m spacy download en_core_web_sm
import spacy
model = spacy.load('en_core_web_sm')
processed = model(text)
for tk in processed:
print(tk.lemma_)
print(tk.pos_)For web scraped texts:
from bs4 import BeautifulSoup, Comment
import re
import html
# Step 1: Parse the HTML content
soup = BeautifulSoup(html_content, 'html.parser')
# Step 2: Remove <script>, <style>, and comments
for script_or_style in soup(['script', 'style']):
script_or_style.decompose()
for comment in soup.find_all(text=lambda text: isinstance(text, Comment)):
comment.extract()
# Step 3: Remove unwanted HTML tags (e.g., <a>, <img>, <iframe>, etc.)
for tag in soup.find_all(['a', 'img', 'iframe', 'button', 'form']):
tag.decompose()
# Step 4: Remove specific noisy elements (e.g., ads, navigation bars)
for ad in soup.find_all(class_='ad'):
ad.decompose()
# Remove navigation bar if exists
nav = soup.find(id='nav')
if nav:
nav.decompose()
# Step 5: Extract text and handle HTML entities
clean_text = soup.get_text()
clean_text = html.unescape(clean_text) # Decode HTML entities
# Step 6: Normalize whitespace (collapse multiple spaces, newlines, etc.)
clean_text = re.sub(r'\s+', ' ', clean_text).strip()
# Step 7: Remove URLs
clean_text = re.sub(r'http[s]?://\S+|www\.\S+', '<URL>', clean_text)
# Clean the HTML
cleaned_text = clean_html(html_content)
print(cleaned_text)N-gram Models
assigns probabilities to sequences of words based on their observed frequencies.
…?
Vectorization
Text to Numbers:
Bag of Words (BoW) represents a document as a collection of words and their frequencies, ignoring grammar and word order.
TF-IDF Model is a more advanced technique for text representation that considers the importance of words in a document relative to the entire corpus.
from sklearn.feature_extraction.text import CountVectorizer, TfidVectorizer
corpus = [text1, text2, ..., textn]
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
print(X) #sparse matrix
import pandas as pd
df = pd.DataFrame(X.toarray(), columns=vectorizer.get_feature_names_out())
print(df)Word Representations:
One Hot:
Embedding Matrix:
The model begins with a one-hot vector representing a word. A one-hot vector is a sparse vector where the position corresponding to the word is set to 1, and all other positions are 0. This one-hot vector is used to retrieve the word’s corresponding vector from the embedding matrix. The embedding matrix is a learnable matrix of size , where is the size of vocabulary., and is the dimensionality of the embedding space.
Training targets:
GloVe (count-based models): The model tries to predict the logarithmic probability of the co-occurrence of a word pair given their embedding, and the objective is to minimize the difference between the predicted and actual co-occurrence values.
Word2Vec (predictive models): The model learns embeddings by trying to predict the surrounding context of a word (using methods like Skip-Gram or Continuous Bag of Words (CBOW)).
!python3 -m spacy download en_core_web_sm
import spacy
model = spacy.load('en_core_web_sm')
processed = model(text)
for tk in processed: print(tk.vector)Deep Learning (TL) SOTAs
(need historical contexts as well)
GPTs:
GPT-1:
Our training procedure consists of two stages. The first stage is a high-capacity language model on a large corpus of text. This is followed by a fine-tuning stage, where we adapt the model to a discriminative task with labeled data.
Given an unsupervised corpus of tokens , we use a standard language modeling objective to maximize the following likelihood: where is the size of the context window, and the conditional probability is modeled using a neural network with parameters . We use a multilayer transformer decoder for the language model, which is a variant of the transformer. This model applies a multi-headed self-attention operation over the input tokens followed by position-wise feedforward layers to produce an output distribution over target tokens as follows: h_0 = UW_e+W_p, ~h_l=\text{transformer block}(h_{l-1})\forall i \in [1,n]$$$$P(u)=\text{softmax}(h_nW_e^T)where is the context vector of tokens, is the number of layers, is the token embedding matrix, and is the position embedding matrix.
After the unsupervised training of model, we adapt the parameters to the supervised target task. We assume a labeled dataset, , where each instance consists of a sequence of input tokens, , along with a label . The inputs are passed through our pre-trained model to obtain the final transformer block’s activation , which is then fed into an added linear output layer with parameter to predict : This gives the following objective to maximize: We additionally found that including language modeling as an auxiliary objective to fine-tuning helped learning by:
- improving generalization of the supervised model
- accelerating convergence
Specifically, we optimize the following objective: Overall, the only extra parameters we require during the fine tuning are , and embeddings for delimiter tokens. For some tasks, like text classification, we can directly fine tune our model as described above. Certain other tasks, like textual entailment, similarity or question answering, have structure inputs such as ordered sentence pairs, or triplet of documents, question and answers. Since our pre-trained model was trained on contiguous sequences of text, we require some modifications to apply it to these tasks.
We use a traversal style approach, where we convert structured inputs into an ordered sequence that the pre-trained model can process. These input transformations allow us to avoid making extensive changes to the architecture across tasks. All transformations include adding randomly initialized start and end tokens.
Classification:

- Sentiment Analysis
- Topic Modeling
- POS
- NER
Entailment:

Similarity:

Multiple Choice:
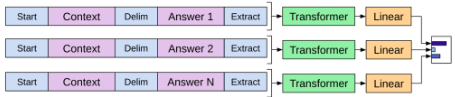
GPT 2:
The capacity of the language model is essential to the success of the zero-shot task transfer and increasing it improves performance in a log-linear fashion across tasks. We demonstrate that language models begin to learn natural language processing tasks, such as
- summarization,
- question answers,
- machine translation etc.
without any explicit supervision when trained on a dataset of millions of webpages.
OpenAI:
OpenAI published its first versions of GPT-3 in July 2020. There were three models, with 1B, 6.7B, 175B parameters, respectively named babbage, curie and davinci (giving initials B, C, and D).
In July 2021, OpenAI published Codex, a task-specific GPT model targeted for programming applications. This was developed by fine-tuning a 12B parameter version of GPT-3 different from previous GPT-3 models using code from GitHub.
In March 2022, OpenAI published two versions of GPT-3 that were fine-tuned for instruction-following (instruction-tuned), named davinci-instruct-beta (175B) and text-davinci-001, and then started beta testing code-davinci-002.
Both text-davinci-003 and ChatGPT were released in November 2022, with both building upon text-davinci-002 via reinforcement learning from human feedback (RLHF). text-davinci-003 is trained for following instructions (like its predecessors), whereas chatGPT is further trained for conversational interaction with a human user.
Other produces of GPT foundation models include EleutherAI, with a series of models in March 2021 and Cerebras with seven models in March 2023.
(GPT’s went on in-context learning spree and left the playground of finetuning stream)
BERTers and it’s descendants
The pre-training process involves first training a tokenizer, followed by training a transformer-based (TB) language model. Traditional word embeddings, such as Word2Vec or GloVe differ from the new contextualized embeddings used in TB models. For example:
Tokenization:
BERT employs WordPiece tokens. The vocabularies of BERT-based models differ. The uncased base model, for example, has 994 tokens set aside for possible fine-tuning. The cased model has only 101 unused tokens because it requires more tokens to cover both uppercase and lowercase letters. Pre-trained BERT comes with a predefined vocabulary of size 30,552, which is also enforced on the pre-trained BERT tokenizer that was applied.
The multilingual mBERT has only 100 unused tokens, but its vocabulary is four times larger than that of uncased. More special characters are stored in multilingual model to cover words of 104 languages.
The GPT2 and RoBERTa implementations share a vocabulary of 50,000 words. They use Byte Pair Encoding (BPE) word pieces with the special signaling character . In contrast to the preceding vocabularies, the XLM employs a suffix signaling tag at the end of word piece to indicate that this is the end of a word. XML employs a BPE-based vocabulary that is shared by multiple langauges and models. While it is true that a bBPE tokenizer trained on a huge monolingual corpus can tokenize any word of any language, it requires on average almost 70% of additional tokens when it is applied to a text in a different language.
This information is key when it comes to choosing a tokenizer to train a natural language model such as a Transformer model. When creating a Transformer tokenizer, two files are typically generated: merges.txt and voab.json. These are the two steps in the tokenization process. The first step is to read the dataset’s input text in string format. After the tokens are generated, in the second step, the tokens are processed through the second file vocab.json, which is simply a mapping file from token-to-token-IDs. These token IDs are read by an embedding layer in the Transformer model during pre-training, which maps the token ID to a dense vector representation of that token.
Pretraining:
Self-supervised, pseudo-labeled data are used in pre-training tasks. The pseudo-labels are determined by the data attributes and the pre-training task definition. To give the model more training signals, a pre-training task should be difficult enough. Futhermore, a pre-training task ought to resemble a downstream task. The pre-training tasks employ various corruption techniques with a fixed corruption rate, such as masking, replacement, or swapping of tokens.
The pretrained model is then modified using the dataset that faithfully represents the issue that needs to be solved. A downstream tasks is what is referred to as the context of self-supervised learning for the latter task. Word representations are updated from labeled data in the downstream task, which is when fine-tuning takes place. While fine-tuning involves adapting the model to a particular task or dataset, pretraining involves training the model on a sizable generic corpus.
Training instability is frequently discovered when fine-tuning TB models. Even when using the same learning rate and batch size values as hyperparameters, different random seeds can result in noticeably different results. The issue becomes even more obvious when using the large Transformers variants on small datasets. The instability of the TB fine-tuning process has been addressed in a number of ways since the introduction of BERT.
Architecture Based Models (ABM) includes:
- S2S Transformers
- Auto-Encoding Transformers
- Auto-Regressive Transformers
Auto-Encoding Transformers:
[Oct, 2018] The BERT is a bidirectional encoder representation model using the Transformer for Language Understanding (LU). As a result of its contribution, the undirectionality constraint was lifted, and an MLM was substituted. After randomly masking some input tokens, the objective is to deduce the masked word’s original vocabulary ID solely from its context. The representation can combine the left and right contexts with the help of the MLM to pre-train a deep bidirectional Transformer. BERT pre-trains text-pair representations through the use of the MLM and the next sentence prediction task (NSP). The pre-trained BERT model can be fine-tuned with just one additional output layer to create SOTA mdoels for a wide range of tasks.
[May, 2019] The UNILM is a BERT-style modified for tasks requiring the generation and comprehension of natural language. The model was pretrained using three different modeling tasks: unidirectional, bidirectional and S2S prediction. Unified modeling is accomplished by utilizing a common network and suitable self-attention masks to control what context the prediction is conditional on.
[Jul, 2019] The ROBERTa is a BERT advancement that changes the pretraining of BERT. The NSP was removed, longer sequence were used for training, and the masking pattern applied to the training data was dynamically changed. The model was also trained over a longer period of time with more data in larger batches.
[Sep, 2019] The ALBERT which stands for light BERT can match BERT’s performance by altering a few scientific parameters in its architecture but only with a small fraction of the parameters and correspondingly lower computational cost.
[Oct, 2019] The DistilBERT is built on BERT and is quicly, less complex, less costly to train than BERT. The distillation in pretraining phase reduces the size of BERT by half while retaining almost language understanding capabilities. The inductive biases are leveraged using a triple loss combining language modeling, distillation and cosine-distance loss.
[Mar, 2020] The ELECTRA trains the discriminator and the generator with two Transformers that replace tokens in the sequence. In addition, masking the input is replaced by the pre-training task known as RTD. The gains are particular strong for small models.
[Apr, 2020] The SMITH is a TB paradigm which makes a number of design choices to adapt self-attention models for extended text inputs. A masked sentence block language modeling task is utilized for model pre-training to capture sentence block relations inside a document, in addition to the basic ML tasks the word level used in BERT. From a series of sentence block representations, the document level Transformers learn the contextual representation for each sentence block and the final document representation.
S2S Transformers:
[May 2019] The MASS adopts the encoder-decoder framework to reconstruct a sentence fragments from its remaining components. The encoder takes a sentence with randomly masked fragment (several consecutive tokens) as input, and its decoder tries to predict this masked fragment. The MASS can then jointly develops the capability of language modeling and representation extraction.
[Oct 2019] The T5 is based on text-to-text framework that provides a simple way to train a single model on a wide variety of tasks using the same loss function and decoding procedure. The most denoising objectives which train the model to reconstruct randomly corrupted text perform similarly in the text-to-text setup.
[Oct 2019] The BART evaluates a number of noising approaches finding the best with random shuffling the order of the original sentences and using a novel in-filling scheme, where spans of text are replaced with a single mask token. BART is particularly effective when fine tuned for text generation but also works well for comprehension tasks.
[Dec 2019] The PEGASUS is pretrained using large document corpora and supervised GSG objective. A pretraining objective that more closely resembles the downstream task leads to better and faster fine-tuning performance. The creation of gap sequences from a document and omitting entire sentences from it serves as an effective pre-training objective for subsequent summary tasks.
Language Based Models:
Multilingual TB models have the advantage of supporting cross-linguistic transfer learning. They can be trained on a particular task in one language and perform reasonably well on the same task in another, despite having only been pre-trained on one language at a time monolingual tasks.
[Oct, 2018] The mBERT is the same architecture BERT was pretrained for the same task on 104 monolingual corpora of distinct languages. Good cross-lingual transfer skills were shown by mBERT. For instance, when mBERT is optimized for a classification task in English, it yields competitive results when evaluated in French.
[May, 2019] The ERNIE incorporates knowledge graphs (KGs) which can provide rich structured knowledge facts for better language understanding. The information entities in KGs can enhance language representation with external knowledge. The experimental results demonstrate the better abilities of both denoising distantly supervised data and fine-tuning on limited data than BERT in Chinese language tasks.
[Jan, 2019] The XLM was pretrained TB architecture using multiple languages which demonstrated the value of cross-lingual pre-training and suggested two approaches for learning cross-lingual language models: an unsupervised approach that only uses monolingual data and another supervised approach that uses parallel data with a new cross-lingual language model objective. The CLM and MLM approaches provide strong cross-lingual features that can be used for pretraining tasks. TLM naturally extends the BERT MLM approach by using bathes of parallel sentences instead of consecutive sentences. The significant gain is by using TLM in addition to MLM.
[Nov, 2019] The XLM-R is trained on 100 languages. The experiment expose a trade-off as scale the number of languages for a mixed model capacity: more languages leads to better cross-lingual performance on low-resource language sup until a point, after which the overall performance and monolingual and cross-lingual benchmarks degrades., and it can be alleviated by simply increasing the model capacity. The model offers significant improvements over previously released multilingual models such as mBERT or XLM.
[Jan, 2020] The mBART on sizable monolingual corpora in numerous languages. It is one of the first techniques for pre-training an entire S2S by denoising full texts in multiple languages.
[Oct, 2020] The mT5 is a multilingual variatnt of T5 pre-trained on dataset covering 101 languages. It also describes a simple technique to prevent accidental translation in the zero-shot setting where a generative model chooses to partially translate its prediction into the wrong language.
[Apr, 2021] The mT6 explores three cross-lingual text-to-text pretraining tasks namely machine translation, translation span corruption and translation pair span corruption. Experimental results show that the purposed mT6 improves cross-lingual transferability over mT5.
Domain Based Models:
???
Task-Based Models:
Benchmarks:
The GLUE bechmarks is a collection of nine natural language understanding tasks, including single-sentence task, similarity and paraphrasing tasks, and natural language inference tasks.
The RACE is a large scale reading comprehension dataset with more than 28,000 passages and nearly 100,000 questions. The dataset is collected from English examinations in China, which are designed for middle school and high school students. The dataset can be used for training and tests sets for machine comprehension.
The SQuAD is a reading comprehension dataset consisting of questions posed by crowd workers on a set of Wikipedia articles where the answer to every question is a segment of text, or span, from the corresponding reading passage, or the question might be unanswerable.
TC Metrics:
- Accuracy
- Precision
- Recall
- F1 Score
- AUC-ROC
- Confusion Matrix
TG Metrics:
BERT
transformers.BertConfigtransformers.BertTokenizer (inherits: transformers.PreTrainedTokenizer)
from_pretrained
__call__(
text (str, List[str], List[List[str]]),
return_tensors = 'pt',
padding (bool, str) = ('max_length','longest', 'do_not_pad')
)
returns {
'input_ids': shape(no_of_strings, sequence_length)
'attention_mask':
'token_type_ids':
}transformers.BertModelForPreTraining,
transformers.BertModel
(config)
forward (
input_ids: shape(batch_size, sequence_length)
attention_mask:
token_type_ids:
)
returns
transformers.models.bert.modeling_bert.BertForPreTrainingOutput
loss (optional)
prediction_logits (batch_size, sequence_length, vocab_size)
seq_relationship_logits (batch_size, 2)
returns transformers.modeling_outputs.BaseModelOutputWithPoolingAndCrossAttentions
last_hidden_state (batch_size, sequence_length, hidden_size)
pooler_output (batch_size, hidden_size)