(Lena-voita)
The idea of the attention mechanism is to permit the decoder to utilize the most relevant parts of the input sequence in a flexible manner, by a weighted combination of all the encoded input vectors, with the most relevant vectors being attributed the highest weights.
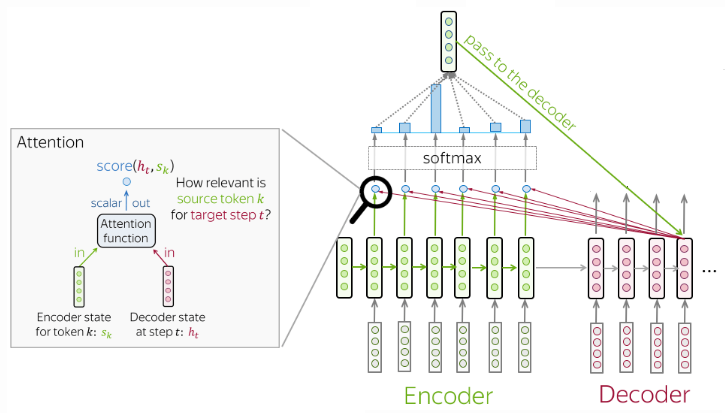
Attention calculates soft weights for each sequence that can change during each runtime, in contrast to hard weights which are pretrained and remain frozen afterwards.
At each decoder step:
- receives attention input: a decoder state and all encoder states;
- computes attention scores: for each encoder state , attention computes its relevance for the current decoder state , formally, it applies an attention function which receives one decoder state and one encoder state and returns a scalar value;
- computes attention weights: probability distribution of attention scores;
- computes attention output: the weighted sum of encoder states with attention weights
The most popular ways to compute attention scores are:
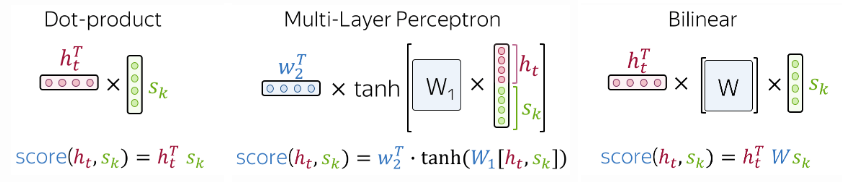
- dot product
- mlp aka Bahdanau attention
- billinear function aka Luong attention
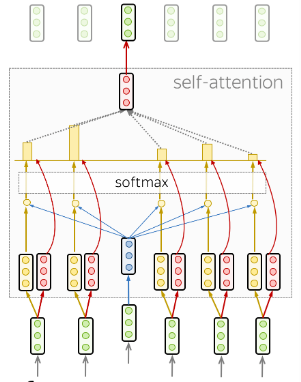
Self-attention:
Self-attention is the part of the model where tokens interact with each other. Each token looks at other tokens in the sentence with an attention mechanism, gathers context, and updates the previous representation of self. In other words, tokens try to understand themselves better in context of each other.
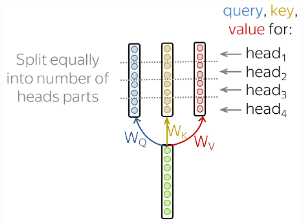
Each input token in self-attention receives three representations corresponding to the roles it can play:
- query - asking for information;
- key - saying that it has some information;
- value - giving the information;
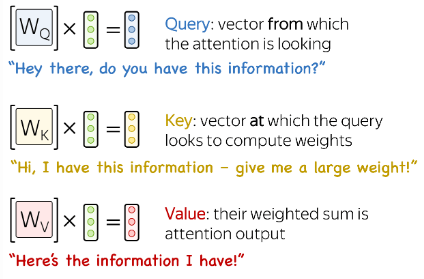
The query is used when a token looks at others - it’s seeking the information to understand itself better.
The key is responding to a query’s request: it is used to compute attention weights.
The value is used to compute attention output: it gives information to the tokens which say they need it.
The transformer uses dot-product self-attention scaled by vector dimensionality of key or value:
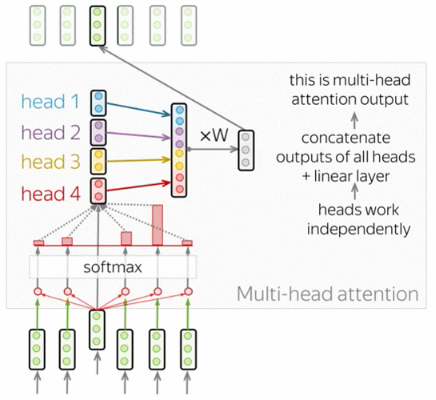
The understanding of a sequence in the input requires understanding it’s relation to other parts as each sequence is part of many relations. The multi-head attention has several heads which work independently. Formally, this is implemented as several attention mechanisms whose results are combined:
where is the linear layer applied at the end of multi-head attention layer.
Multi-head attention does not increase model size:
Text classification
(just stack some LSTM then do it, right?)
Sequence to sequence
- RNN seq2seq
- RNN seq2seq (with attention)
- CNN seq2seq
- Transformers
- BERT
The seq2seq uses a RNN encoder to emit the context usually as a simple function of its final hidden state and decoder RNN is conditioned on that fixed-length vector to generate the output sequence.
The innovation of such architecture is that the lengths of the sequences can vary from each other.
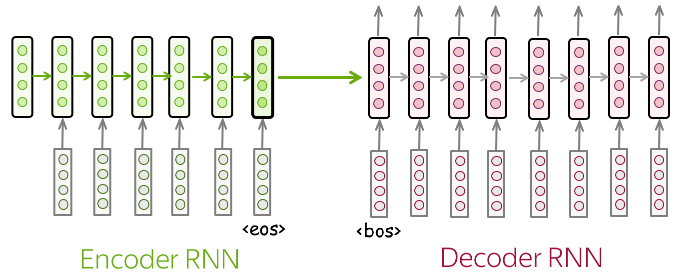
The architecture fails to learn long term dependencies if the fixed length context vector cannot compress longer sequences into a representation which model the information present in the input.
TRANSFER LEARNING IS HARD FOR THESE NETWORKS BECAUSE WE HAVE NO IDEA WHAT IS LEARNT AT EACH LAYERS
Transformers
The transformer architecture is solely based on attention mechanisms without recurrence. Intuitively, transformer’s encoder can be thought of as a sequence of reasoning steps. At each step, tokens look at each other, exchange information through self-attention and try to understand each other better in the context of the whole sentence. In each decoder layer, tokens of the prefix also interact with each other via a self-attention mechanism, but additionally, they look at the encoder states.
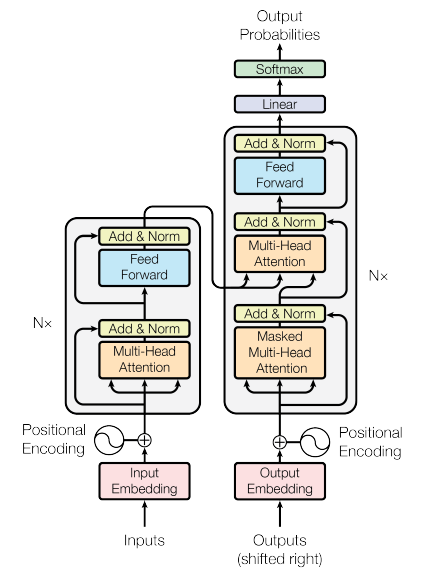
Feed-forward layers: Each layer has a feed-forward network block: two linear layers with ReLU non linearity between them.
(feedforward ko bich ma chai relu lagako xa originally)
(not clear on this architecture but dropout is applied to attention just after so doesnot add to 1 and also before sending into add and norm)
Attention: “Look at other tokens and gather information”
FFN: “Take a moment to think and process this information” (not clear on this architecture but dropout is applied to attention just after so doesnot add to 1 and also before sending into add and norm)
Positional encoding:
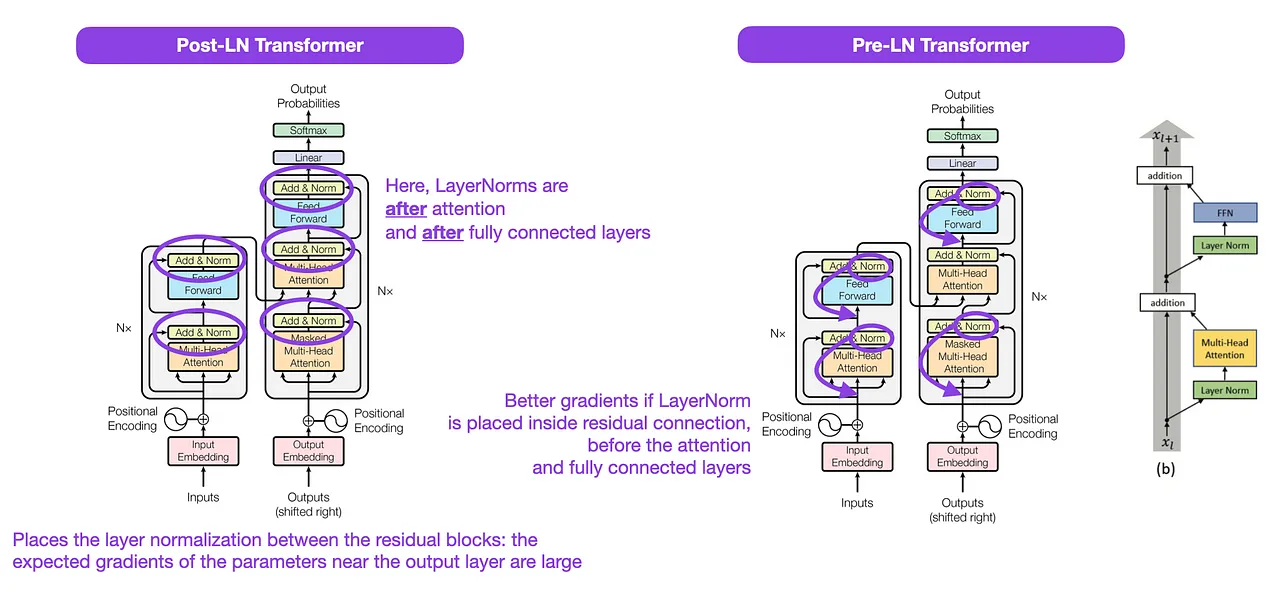
The original transformer places the layer normalization between the residual blocks. The variant shown in figure is known as post-LN transformer. The experiments suggest that pre-LN works better, addressing gradient problems. Many architectures adopted this in practice, but it can result in representation collapse.
Transformers in analysis
The disadvantages of transformer is that the self-attention is squared operation on length of the sequence, so its hard for images given that these are 2Ds since every single pixel need to attain to every other pixels.
TFF is the local attention?
Transfer Learning NLP
Previous: Word2Vec, GloVe,
Sentence level: ELMo, ULMFit
Transformer and some changes: GPT, BERT
Universal Language Model Fine-tuning for Text Classification (by Howard, there is a youtube video)
- it doesn’t involve transformers but instead focuses on recurrent neural networks
- While transfer learning was already established in computer vision, it wasn’t yet prevalent in natural language processing (NLP). ULMFit was among the first papers to demonstrate that pretraining a language model and finetuning it on a specific task could yield state-of-the-art results in many NLP tasks.
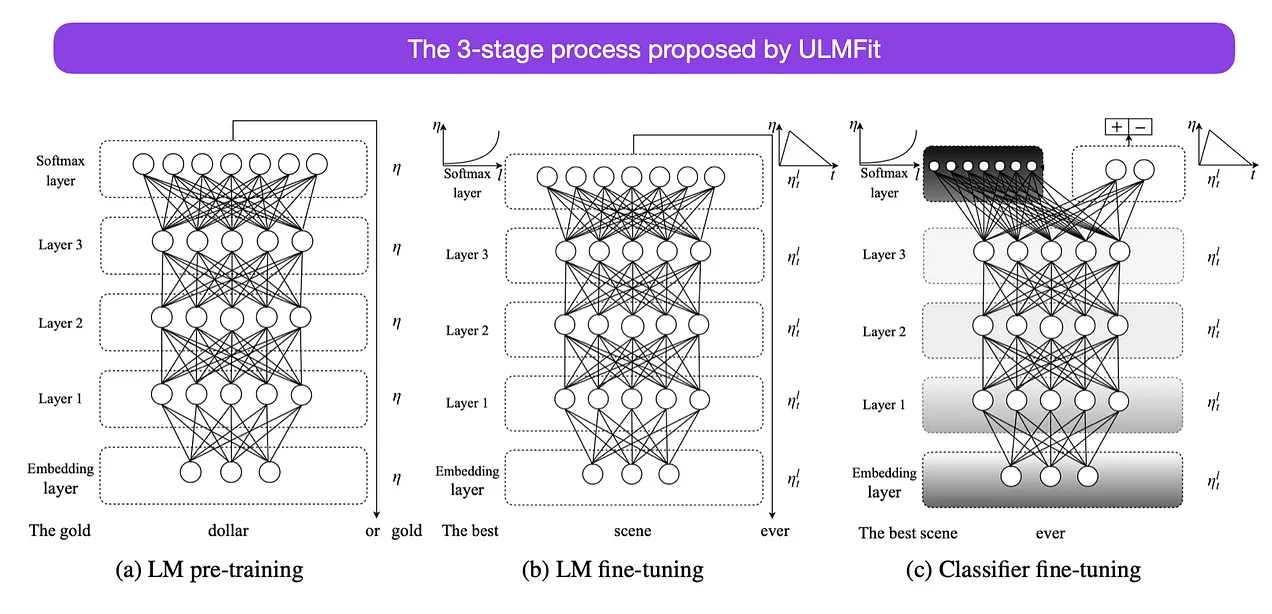
- THe three-stage process for finetuning the language models suggested by UMLFit was as follows:
- Train a language model on a large corpus of text
- Finetune this pretrained language model on task-specific data, allowing it to adapt to the specific style and vocabulary of the text
- Finetune a classifier on the task-specific data with gradual unfreeezing of layers to avoid catastrophic foregetting
This recipe — training a language model on a large corpus and then finetuning it on a downstream task — is the central approach used in transformer-based models and foundation models like BERT, GPT-2/3/4, RoBERTa, and others.
However, the gradual unfreezing, a key part of ULMFiT, is usually not routinely done in practice when working with transformer architectures, where all layers are typically finetuned at once.
One analysis papaer rey: by 98 coauthors wala ??? Gopher
Benchmarking:
- GLUE: The GLUE is a collection of 9 datasets for evaluating natural language understanding systems. Tasks are framed as either single-sentence classification or sentence-pair classification tasks.
- SQuAD: The Stanford Question Answering Dataset provides a paragraph of context and a question. The task is to answer the question by extracting the relevant span from the context. In V1.1 the context always contains an answer, whereas in V2.0 some questions are not answered in the provided context, making the task more challenging.
- RACE: The ReAding Comprehensions from Examinations (RACE) task is a large-scale reading comprehension dataset with more than 28,000 passages and nearly 100,000 questions. The dataset is collected from English Examinations in China, which are designed for middle and high school students. In RACE, each passage is associated with multiple questions. For every question, the task is to select one correct answer from four options. RACE has significantly longer context than other popular reading comprehension datasets and the proportion of q
Note: Sparse attention variants not only reduce the computational complexity but also introduce structural prior on input data to alleviate the overfitting problem on small datasets.
Survey on Transformers
The X-formers improve the vanilla Transformer from different perspective:
- Model efficiency: A key challenge of applying T is its inefficiency at processing long sequences mainly due to the computation and memory complexity of self-attention module. The improvement methods include lightweight attention (e.g. sparse attention variants) and Divide-and-conquer methods (e.g. recurrent and hierarchical mechanism)
- Model generalization: Since the transformer is a flexible architecture and makes few assumptions on the structural bias of input data, it is hard to train on small-scale data. The improvement methods include introducing structural bias or regularization, pre-training on large-scale unlabeled data, etc
- Model adaptation: This line of work aims to adapt the T to specific downstream tasks and applications.
Vanilla Transformer:
is a seq2seq model and consists of an encoder and a decoder, each of which is a stack of identical blocks. Each encoder block is mainly composed of a multi-head self-attention module and a position-wise feed-forward network (FFN). For building a deeper model, a residual connection is employed around each module, followed by Layer Normalization. Compared to the encoder blocks, decoder blocks additionally insert cross-attention modules between the multi-head self-attention modules and the position-wise FFNs. Furthermore, the self-attention modules in the decoder are adapted to prevent each position from attending to subsequent positions.
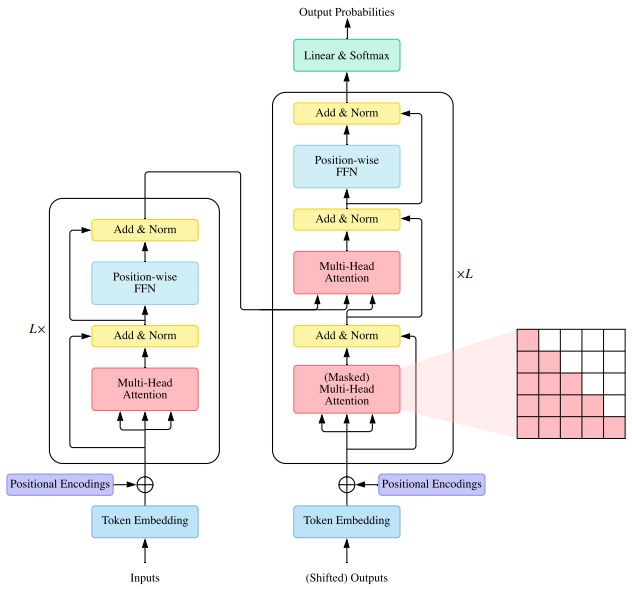
Attention modules: Transformer adopts attention mechanism with Query-Key-Value (QKV) model. Given the packed matrix representations of queries , keys , and values , the scaled dot-product attention used by Transformer is given by: where and denote the lengths of queries and keys (or values); is often called attention matrix; softmax is applied in a row-wise manner. The dot-products of queries and keys are divided by to alleviate gradient vanishing problem of softmax function.
Instead of simply applying a single attention function, Transformer uses multi-head attention, where the -dimensional original queries, keys and values are projected into and dimensions, respectively, with diferent sets of learned projections. For each of the projected queries, keys and values, and output is computed with attention according to above. The model then concatenates all the outputs and projects them back to -dimensional representation. where, In Transformer, there are three types of attention in terms of the source of queries and key-value pairs:
- Self-attention:
- Masked self-attention:
- Cross-attention: …
Model analysis: To illustrate the computation time and parameter requirements of the Transformer, we analyze the two core components of the Transformer (i.e., the self-attention module and the position-wise FFN). We assume that the hidden dimension of the model is , and that the input sequence is . The intermediate dimension of FFN is set to and the dimension of keys and values are set to :
| Module | Complexity | Parameters |
|---|---|---|
| self-attention | ||
| position-wise FFN |
- When the input sequences are short, the hidden dimension dominates the complexity of self-attention and position-wise FFN. The bottleneck of Transformer thus lies in FFN.
- However, as the input sequences grow longer, the sequence length gradually dominates the complexity of these modules, in which case self-attention becomes the bottleneck of Transformer. Furthermore, the computation of self-attention requires that a 𝑇 × 𝑇 attention distribution matrix is stored, which makes the computation of Transformer infeasible for long-sequence scenarios (e.g., long text documents and pixel-level modeling of high-resolution images).
Comparing to other types: